R4DS Exercises

Ralph can and you can too
Overview
I’m guiding a group walkthrough of Garrett Grolemund and Hadley Wickam’s great book R for Data Science. We are trying to cover a chapter of material per week and have a one-hour weekly code review to sit together and discuss the Excersises. If you live around Charlottesville and are interested in joining, ping me.
These are the answers to the excercises we have covered so far and will update after our mostly weekly meetings.
3 Intro to ggplot2
3.2 First Steps
library(magrittr) # %<>%
library(tidyverse)- Run ggplot(data = mpg). What do you see?
ggplot(mpg) # grey square
# this is the initialized plotting area- How many rows are in mpg? How many columns?
dim(mpg)## [1] 234 11- What does the drv variable describe? Read the help for ?mpg to find out.
?mpg - Make a scatterplot of hwy vs cyl.
ggplot(mpg) +
geom_point(aes(x = hwy, y = cyl))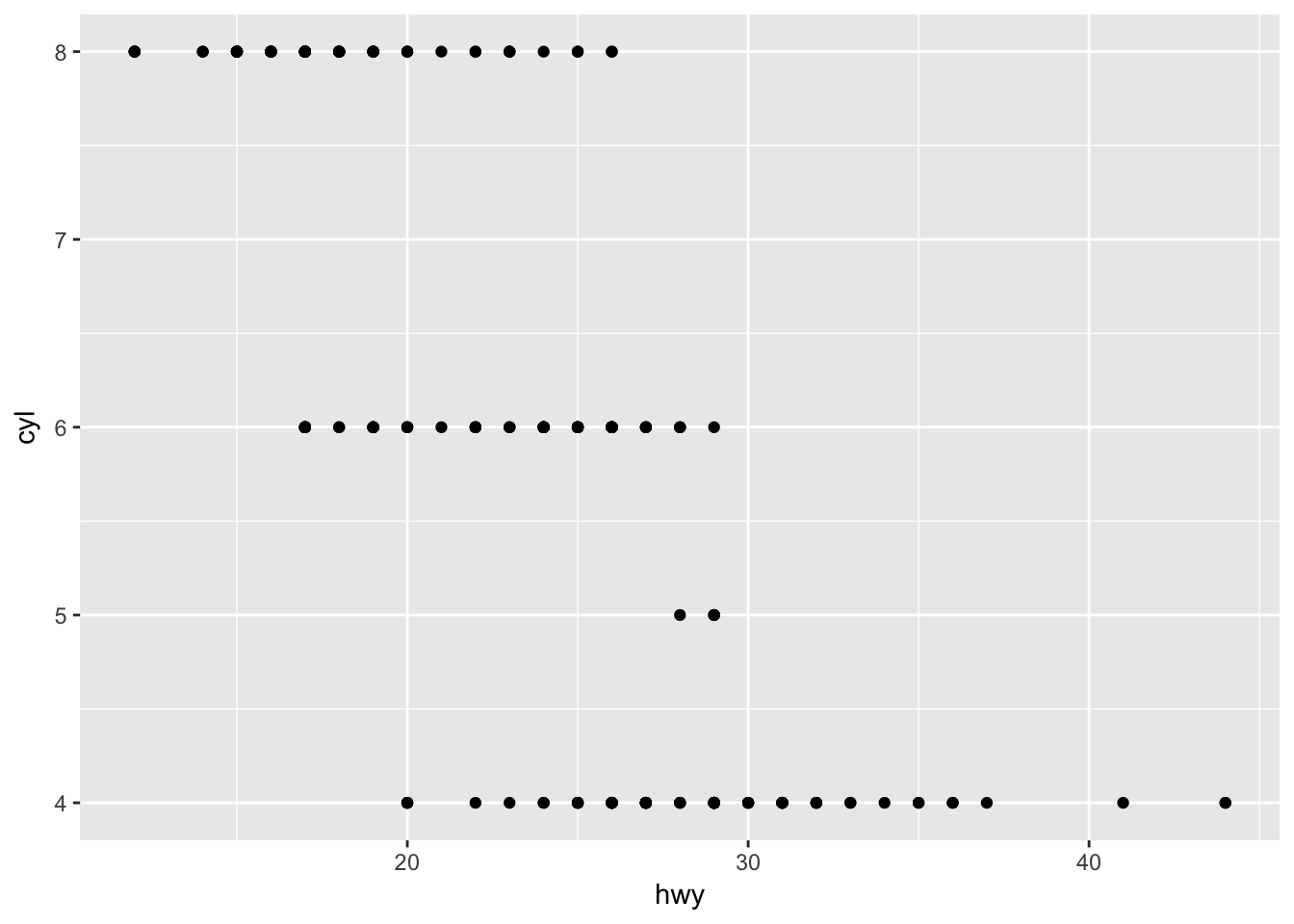
- What happens if you make a scatterplot of class vs drv? Why is the plot not useful?
ggplot(mpg) +
geom_point(aes(x = class, y = drv))# factor vs factor points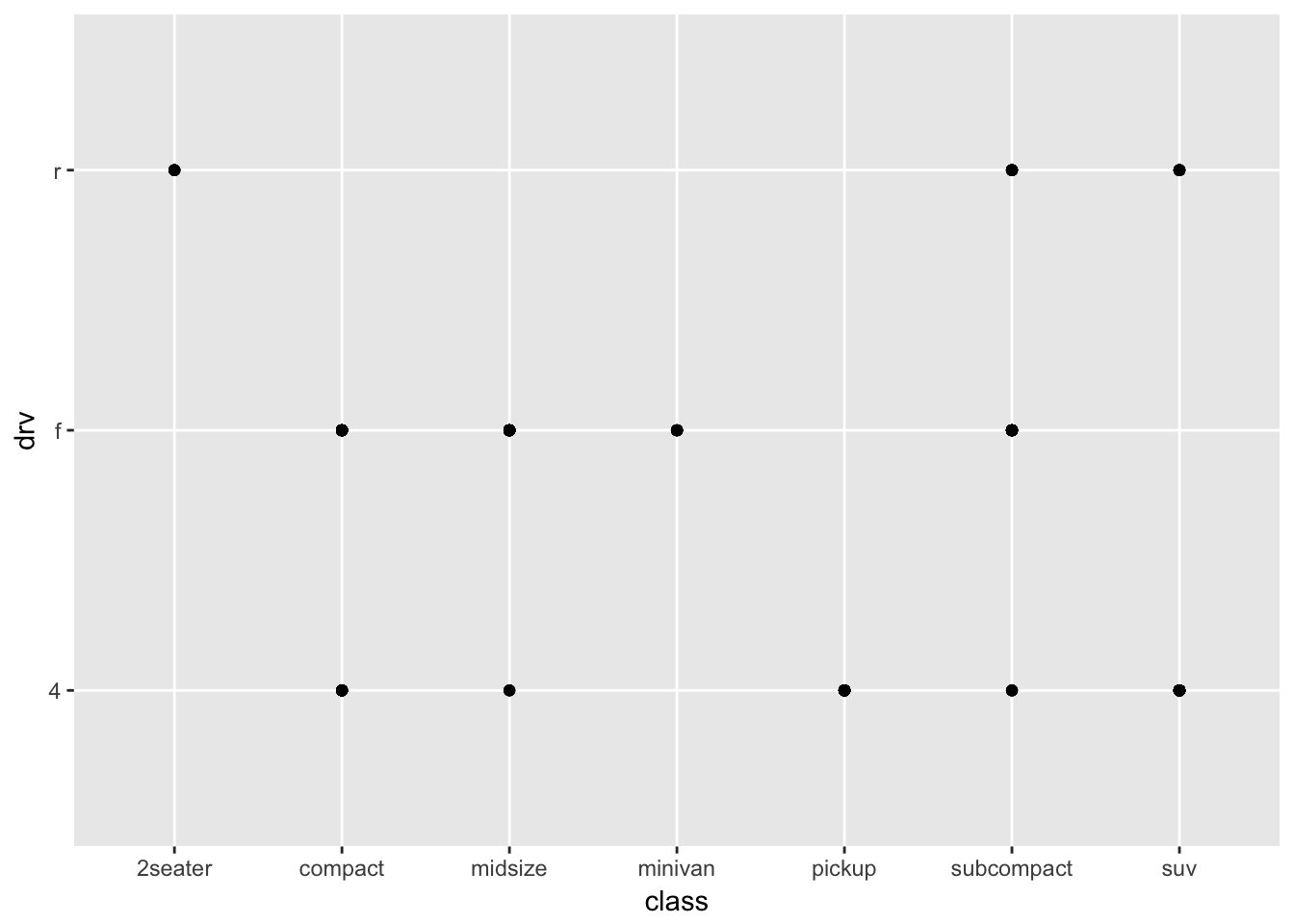
# need some sort of density/count viz instead3.3 Aesthetics
- What’s gone wrong with this code? Why are the points not blue?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = "blue"))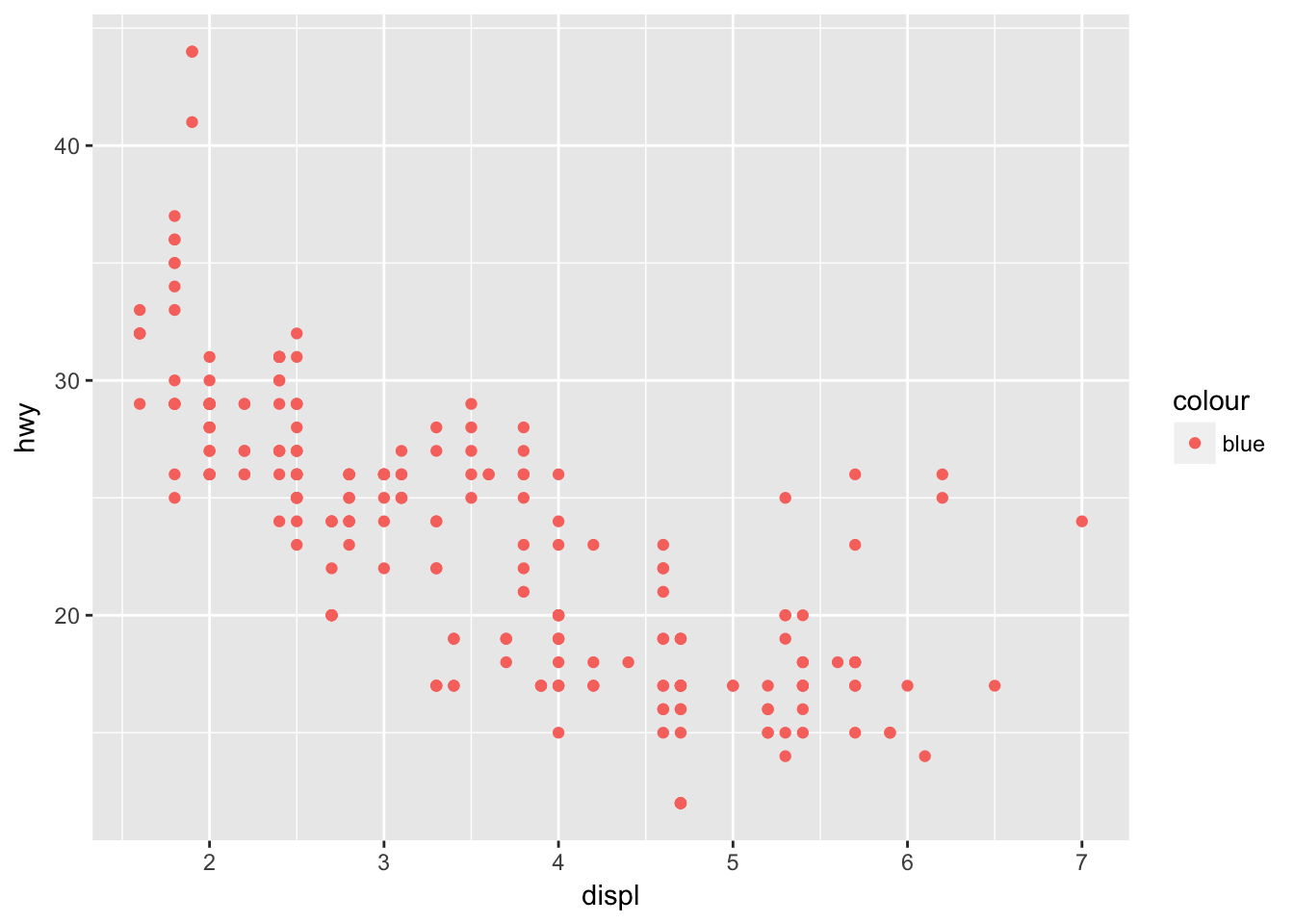
# aes is for mapping columns in mpg by name
# doesn't understand color names inside aes() so uses default color scale
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = "blue")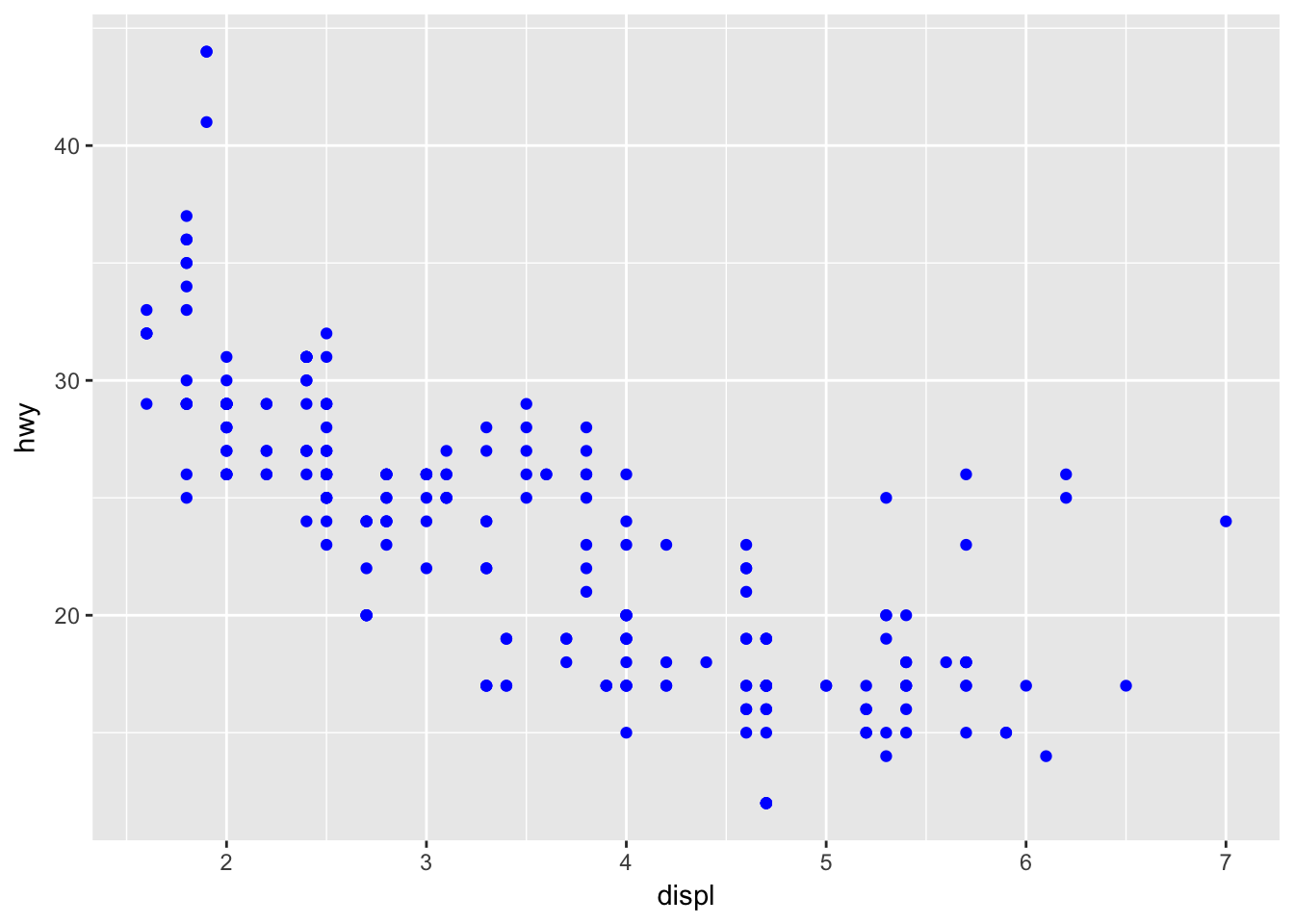
# just move it outside- Which variables in mpg are categorical? Which variables are continuous? (Hint: type ?mpg to read the documentation for the dataset). How can you see this information when you run mpg?
str(mpg) # chr/fct is categorical, int/num is numeric## Classes 'tbl_df', 'tbl' and 'data.frame': 234 obs. of 11 variables:
## $ manufacturer: chr "audi" "audi" "audi" "audi" ...
## $ model : chr "a4" "a4" "a4" "a4" ...
## $ displ : num 1.8 1.8 2 2 2.8 2.8 3.1 1.8 1.8 2 ...
## $ year : int 1999 1999 2008 2008 1999 1999 2008 1999 1999 2008 ...
## $ cyl : int 4 4 4 4 6 6 6 4 4 4 ...
## $ trans : chr "auto(l5)" "manual(m5)" "manual(m6)" "auto(av)" ...
## $ drv : chr "f" "f" "f" "f" ...
## $ cty : int 18 21 20 21 16 18 18 18 16 20 ...
## $ hwy : int 29 29 31 30 26 26 27 26 25 28 ...
## $ fl : chr "p" "p" "p" "p" ...
## $ class : chr "compact" "compact" "compact" "compact" ...- Map a continuous variable to color, size, and shape. How do these aesthetics behave differently for categorical vs. continuous variables?
ggplot(mpg, aes(displ, cty, color = hwy)) +
geom_point() + # continuous graident
labs(title = "Color")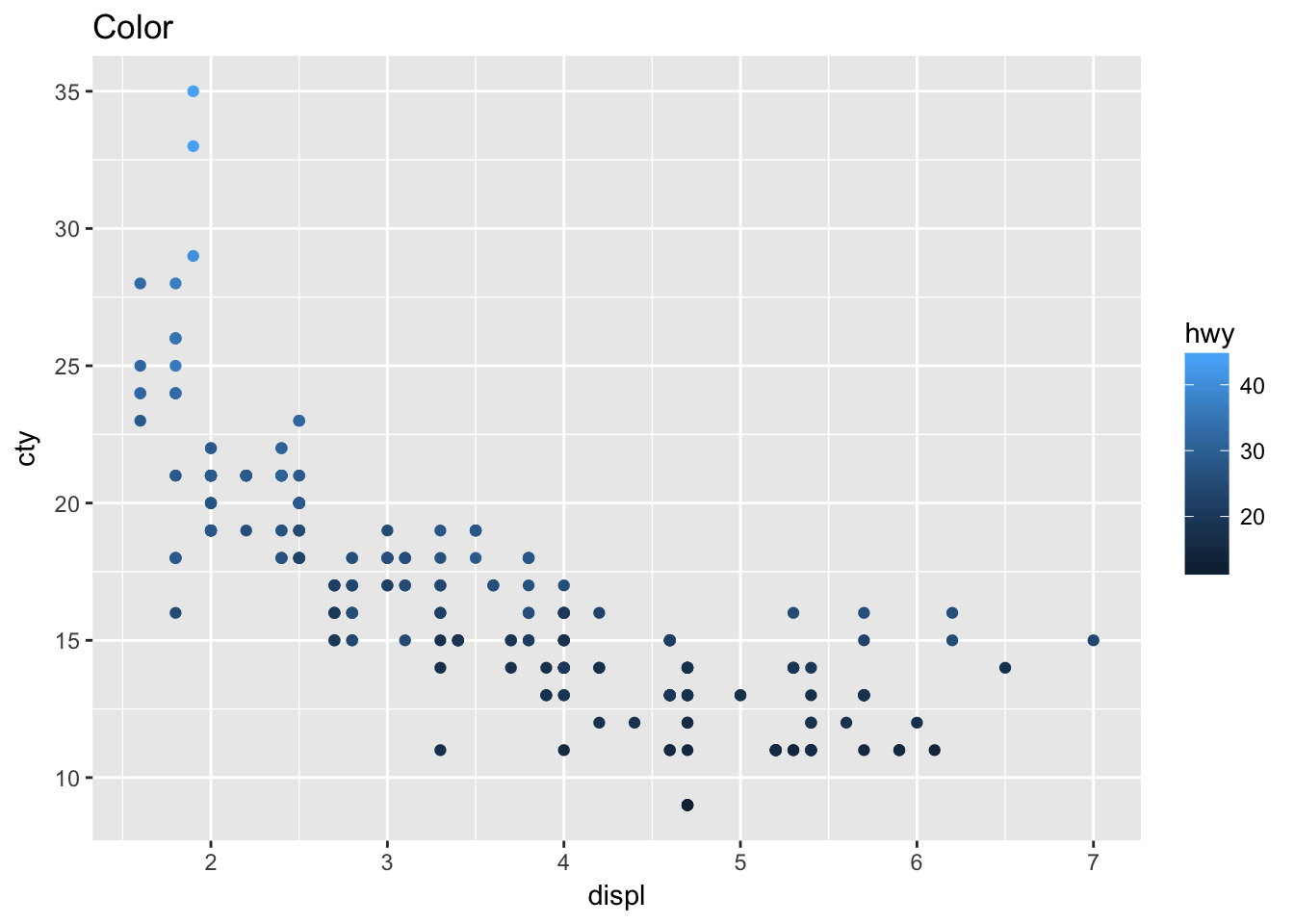
ggplot(mpg, aes(displ, cty, size = hwy)) +
geom_point() + # continuous gradient
labs(title = "Size")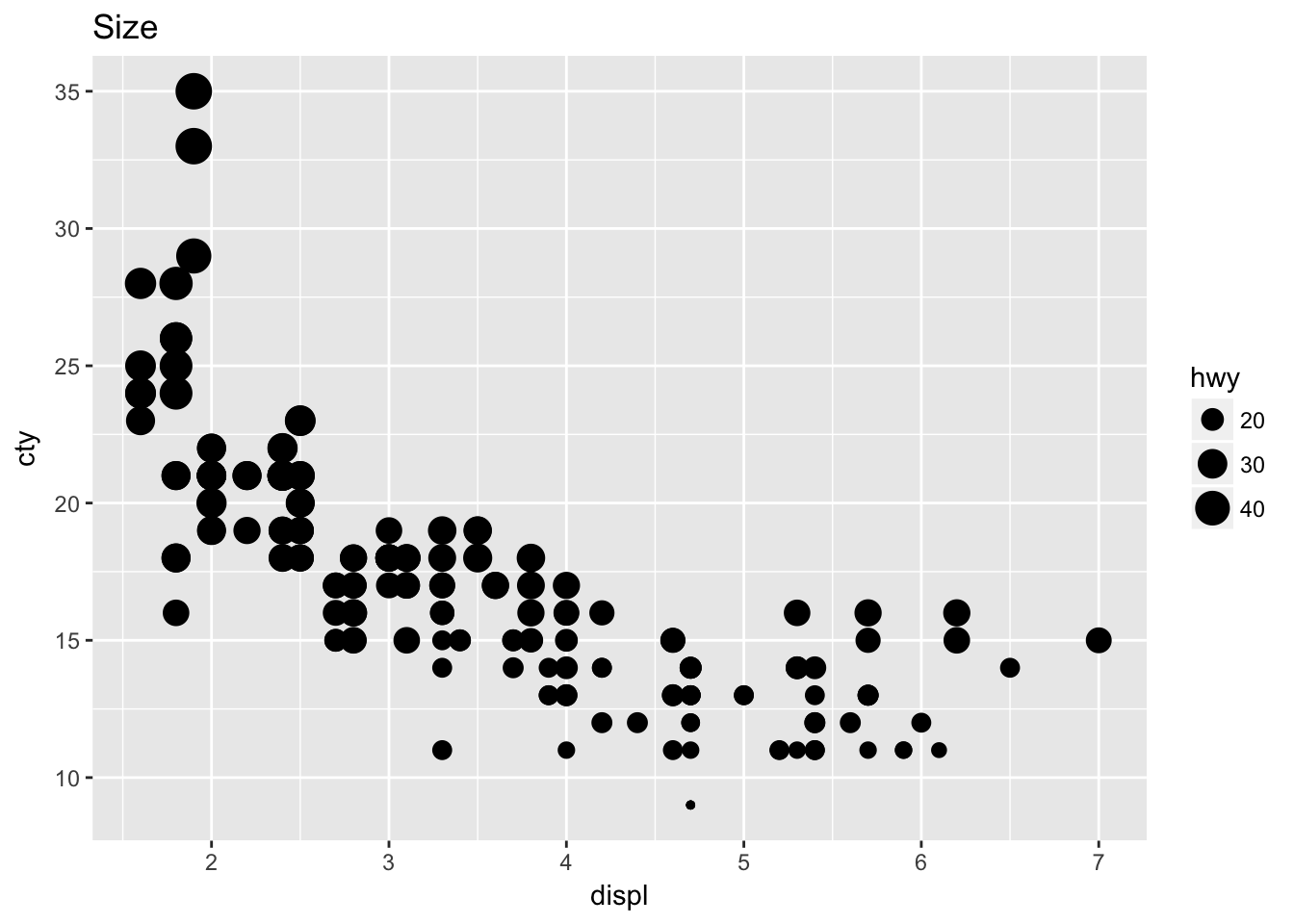
# Error: A continuous variable can not be mapped to shape
ggplot(mpg, aes(displ, cty, shape = hwy)) +
geom_point() + # can't map continuous to shape
labs(title = "Shape")- What happens if you map the same variable to multiple aesthetics?
ggplot(mpg, aes(displ, cty, fill = trans)) +
geom_point(shape = 21, size = 4)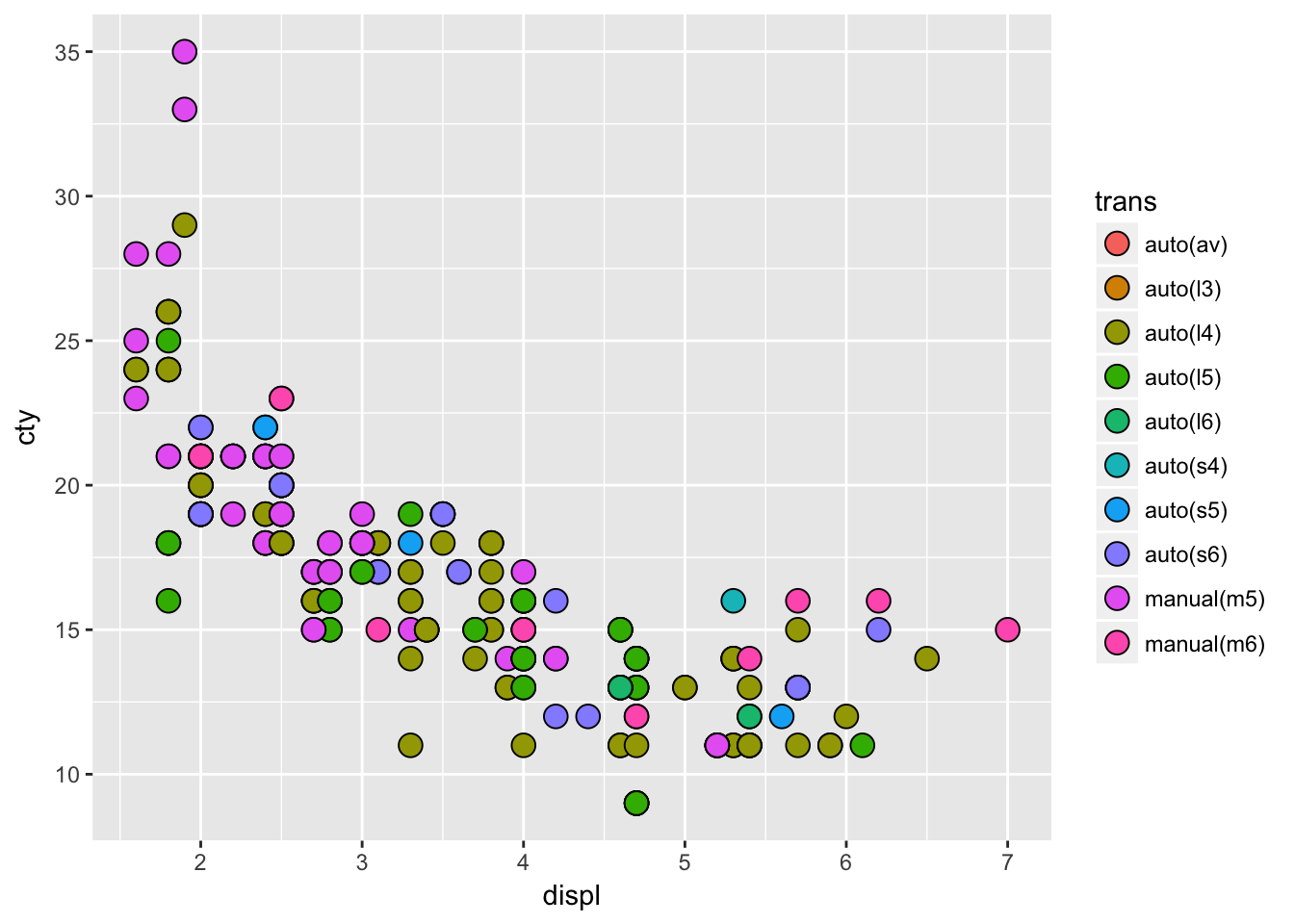
# you waste resolution- What does the stroke aesthetic do? What shapes does it work with? (Hint: use ?geom_point)
ggplot(mpg, aes(displ, cty, fill = trans)) +
geom_point(stroke = 2, shape = 21, size = 4)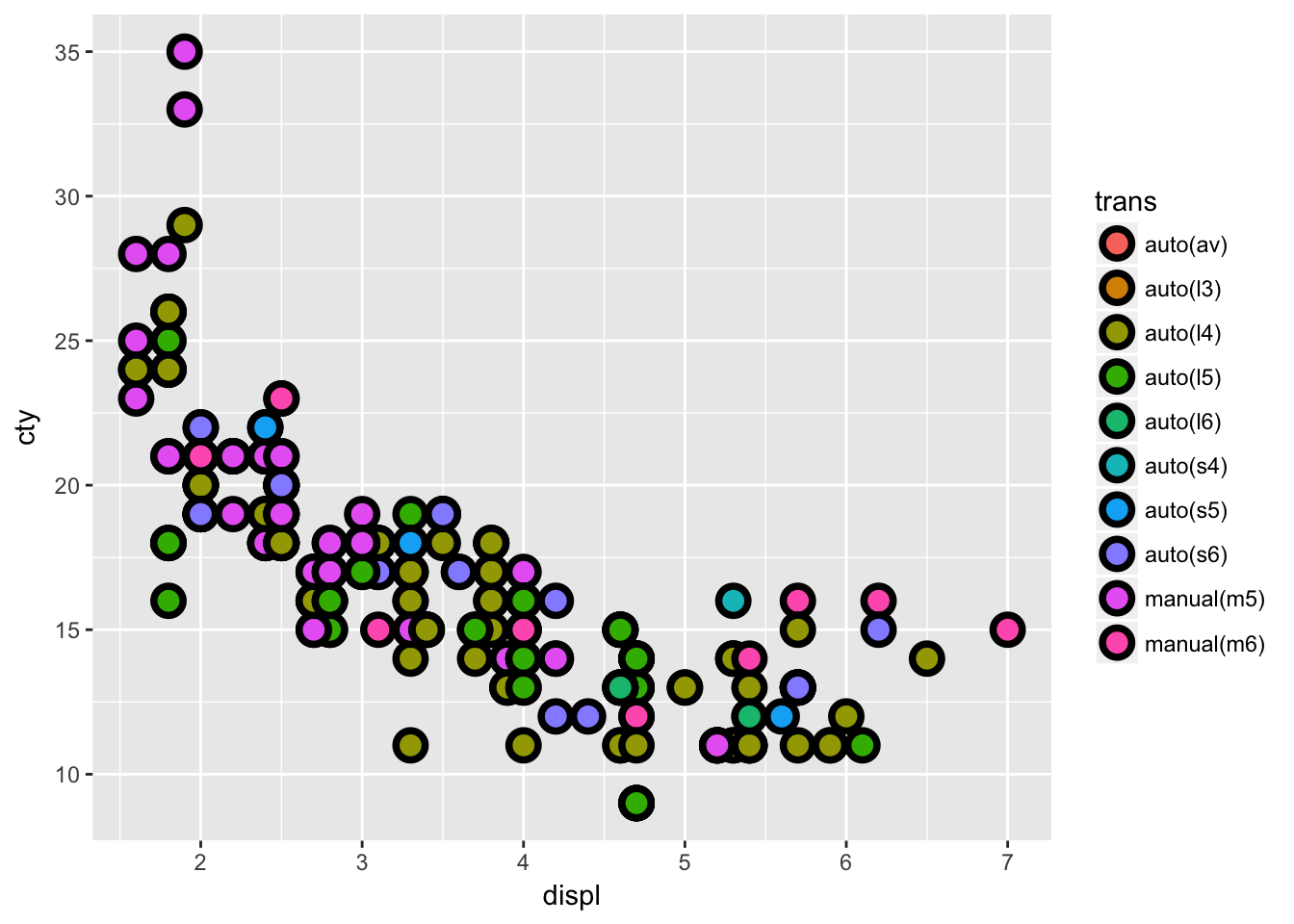
# stroke is the outline thickness of shapes 21:25- What happens if you map an aesthetic to something other than a variable name, like aes(colour = displ < 5)?
ggplot(mpg, aes(drv)) +
geom_bar() +
facet_wrap(~hwy) # bins it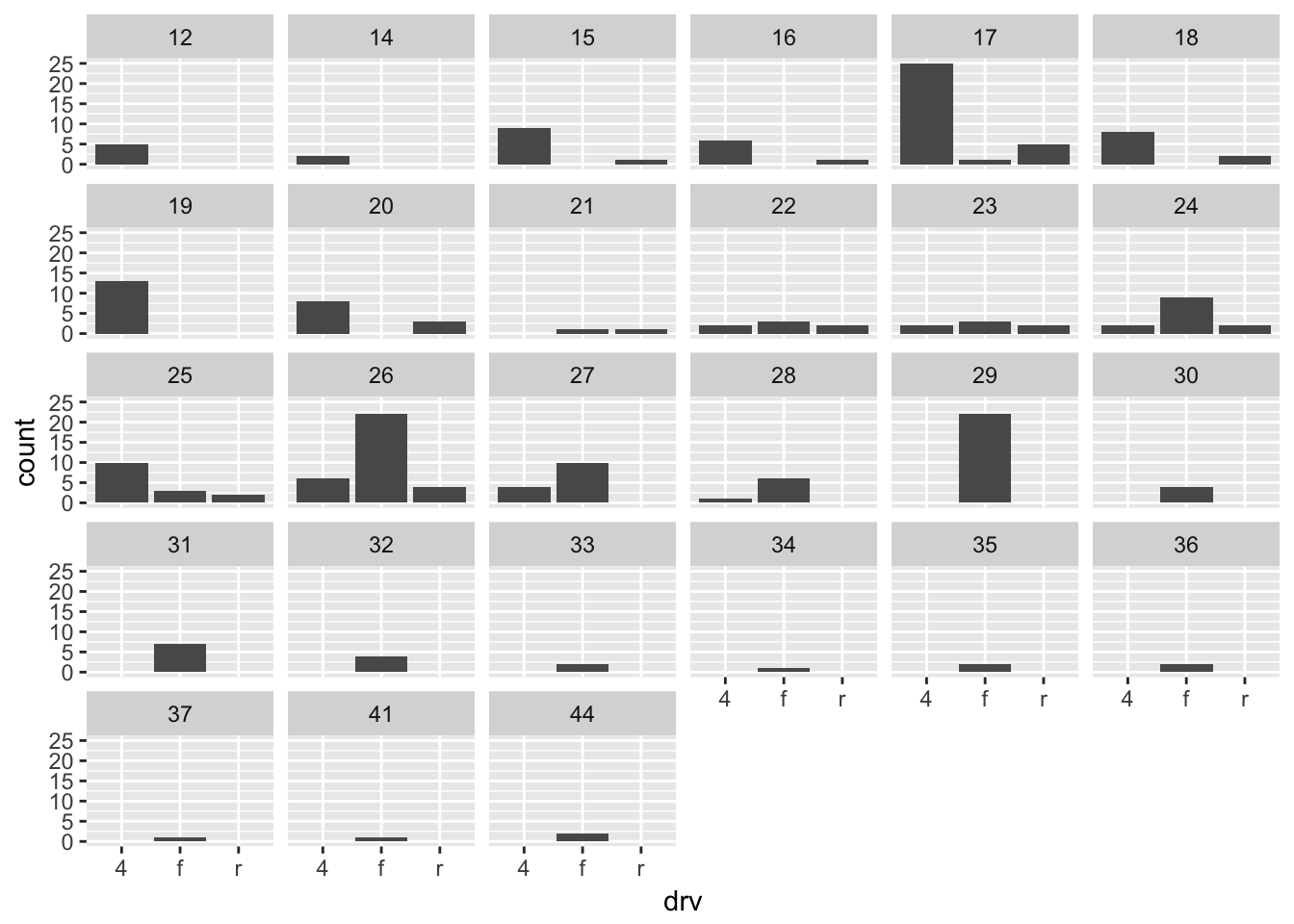
3.5 Facetting
- What happens if you facet on a continuous variable?
ggplot(mpg, aes(drv)) +
geom_bar() +
facet_wrap(~hwy) # coherces to intervals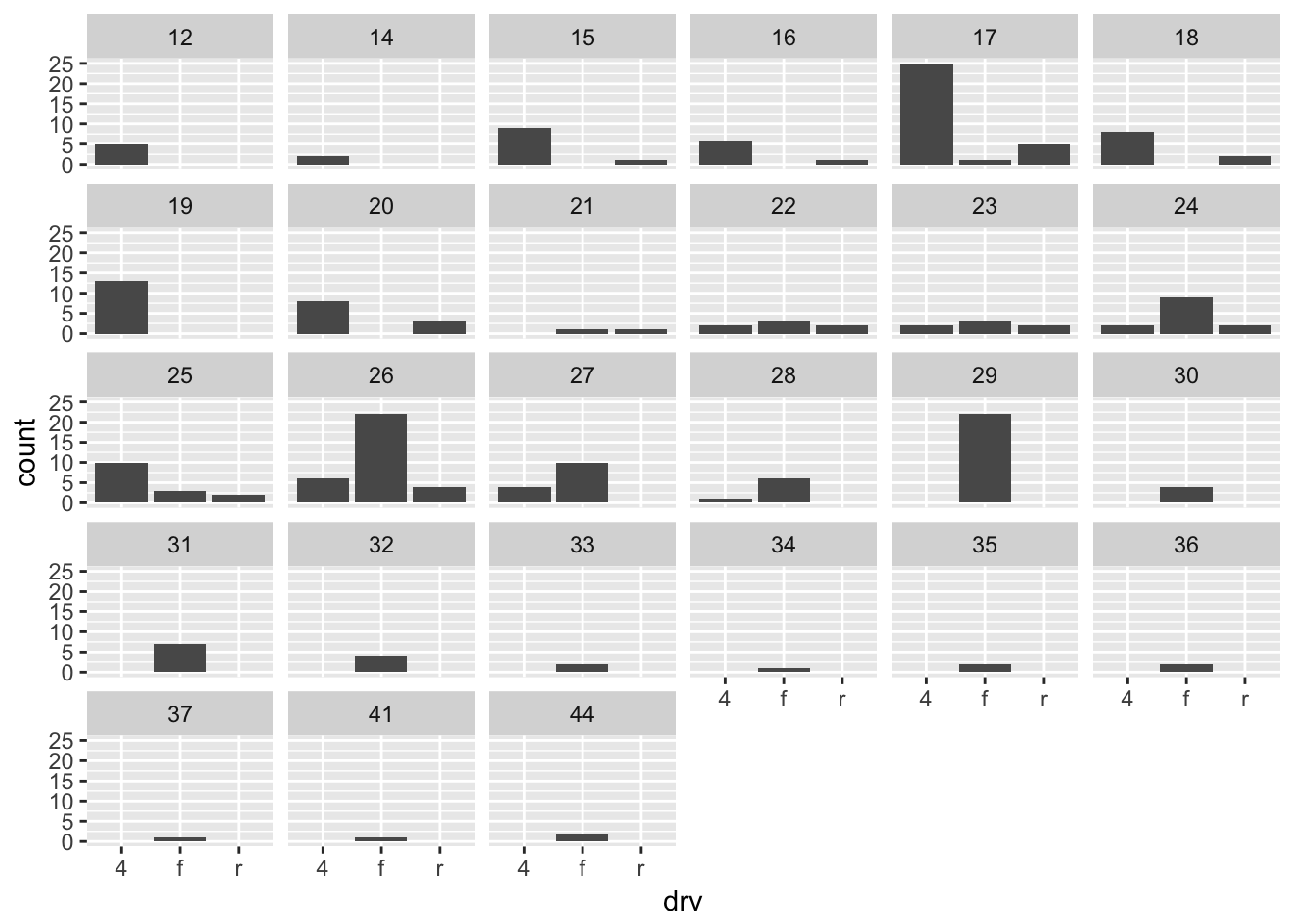
- What do the empty cells in plot with facet_grid(drv ~ cyl) mean? How do they relate to this plot?
ggplot(data = mpg) +
geom_point(mapping = aes(x = drv, y = cyl)) +
facet_wrap(drv ~ cyl) # combinations do not exist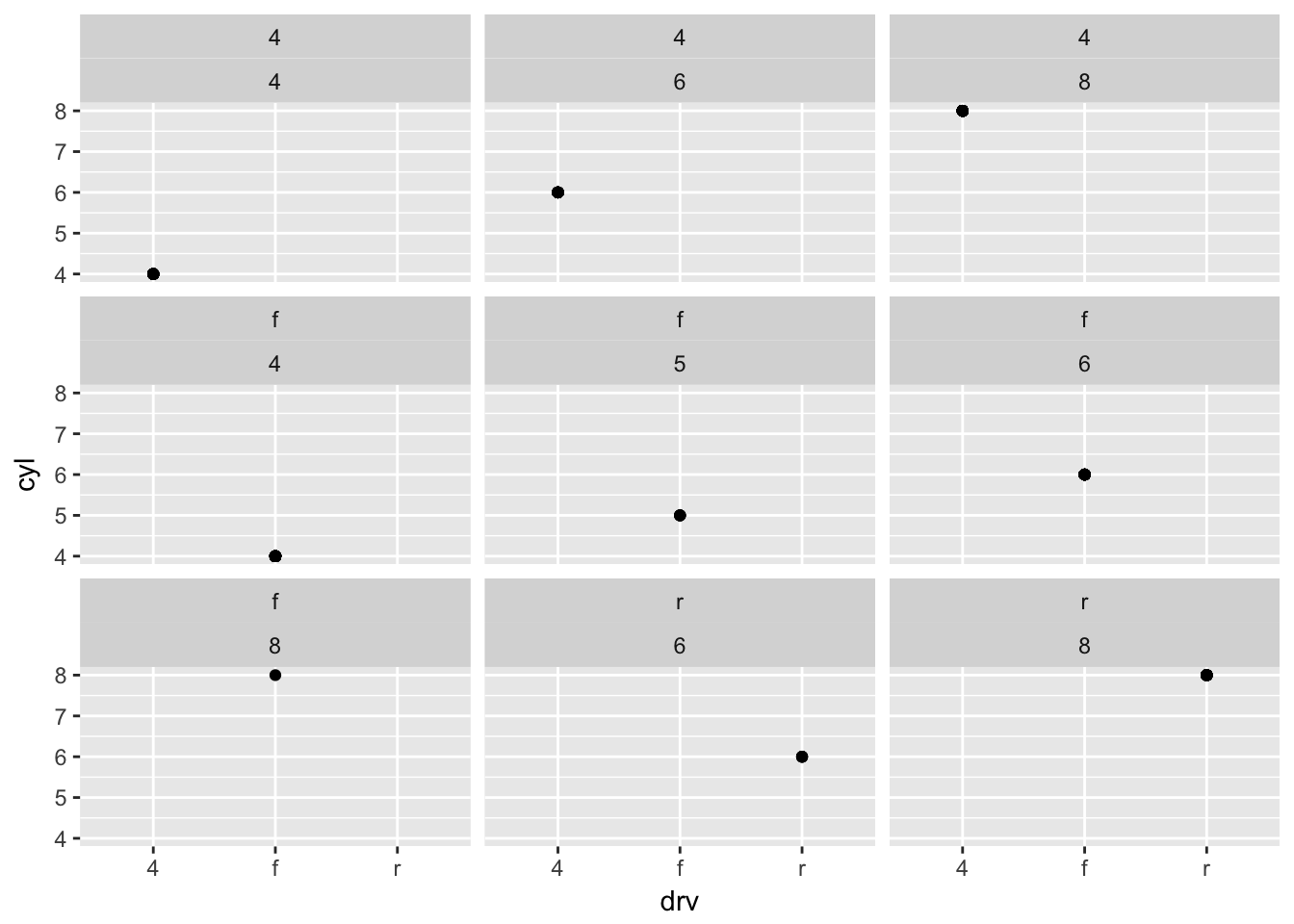
# facet_wrap() will drop them - What plots does the following code make? What does . do?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ .) # compares against nothing if var is first (facets on y)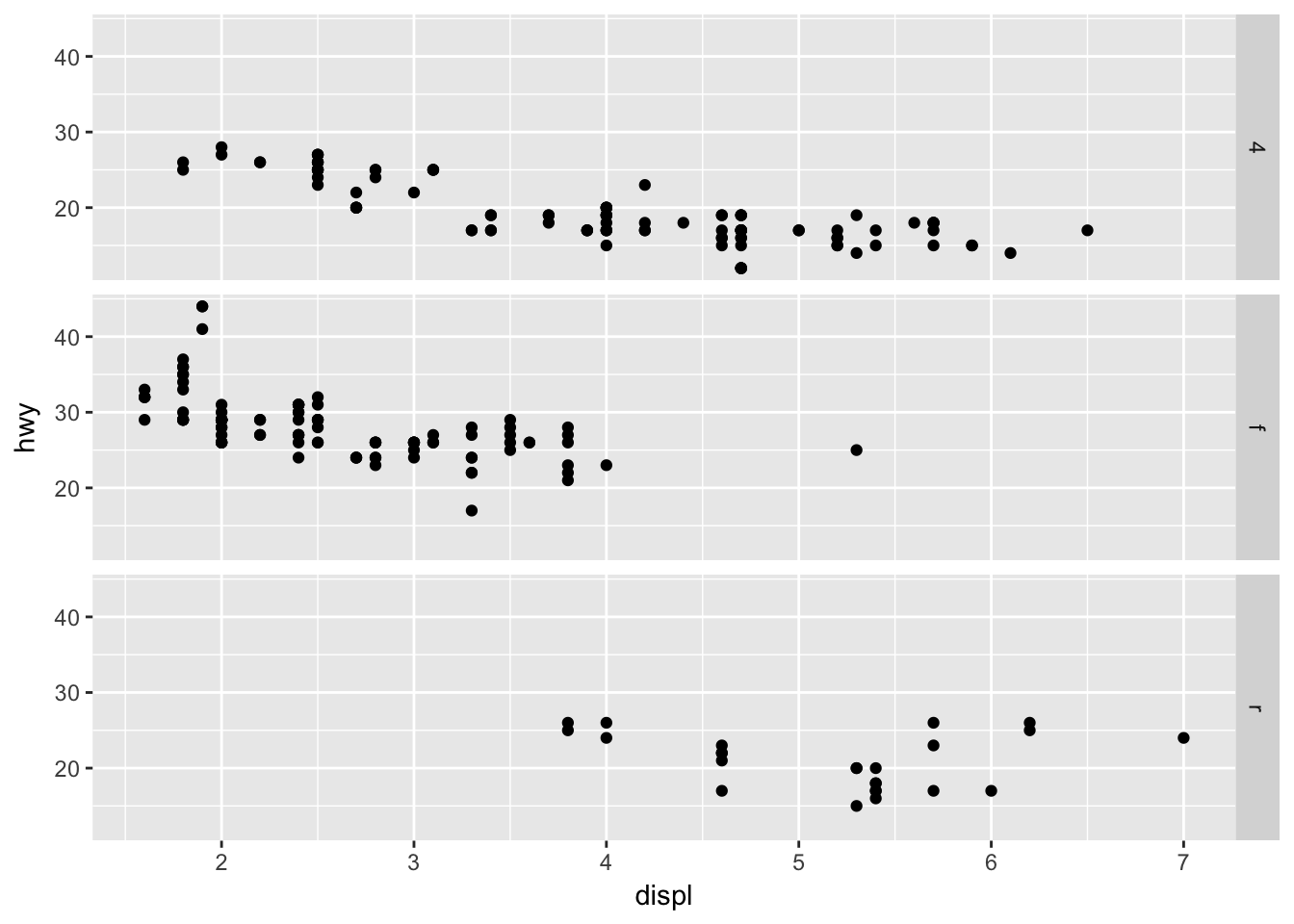
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(~ cyl) # don't need a dot if var is second (facets on x)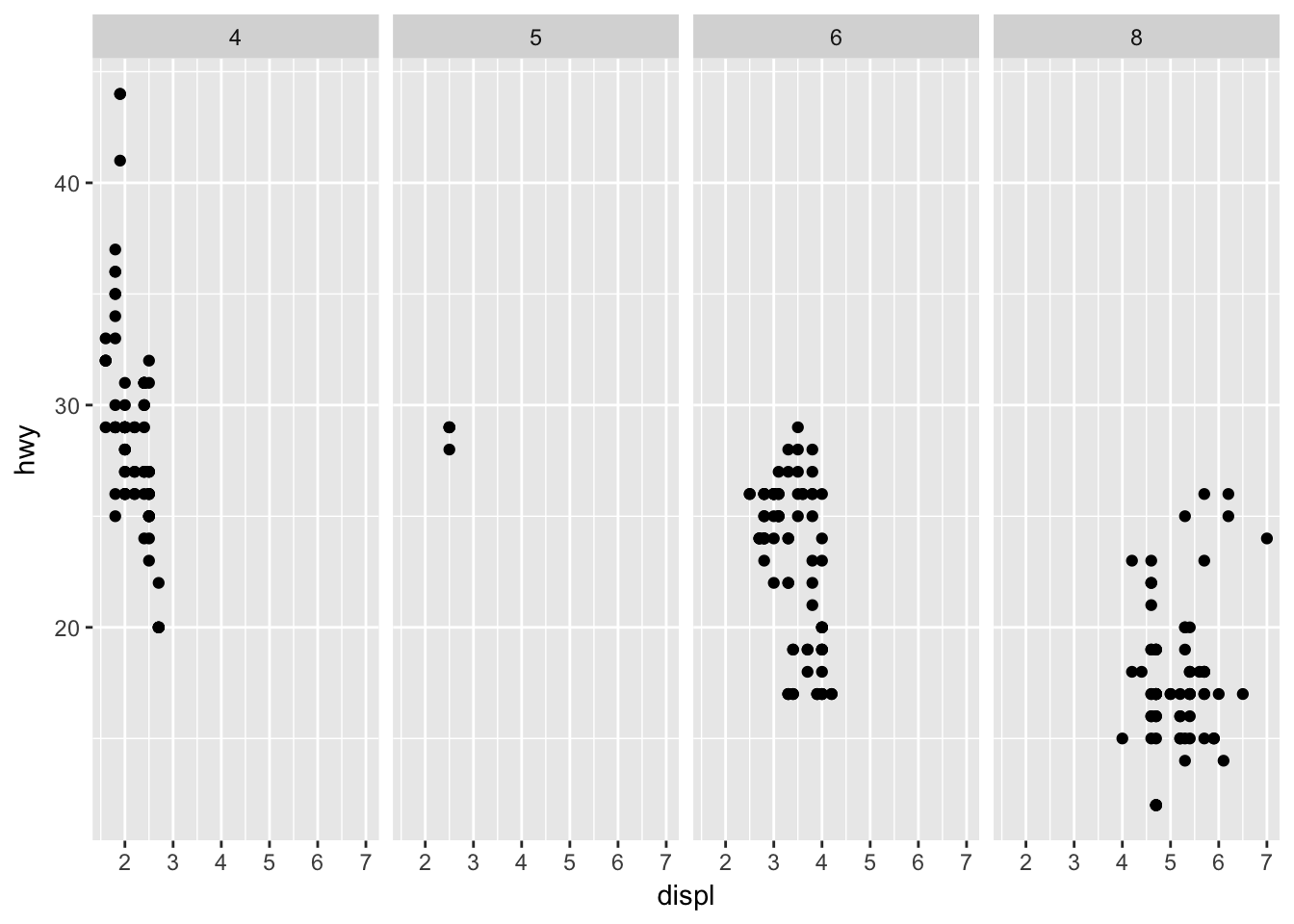
- Take the first faceted plot in this section: What are the advantages to using faceting instead of the colour aesthetic? What are the disadvantages? How might the balance change if you had a larger dataset?
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class, nrow = 2)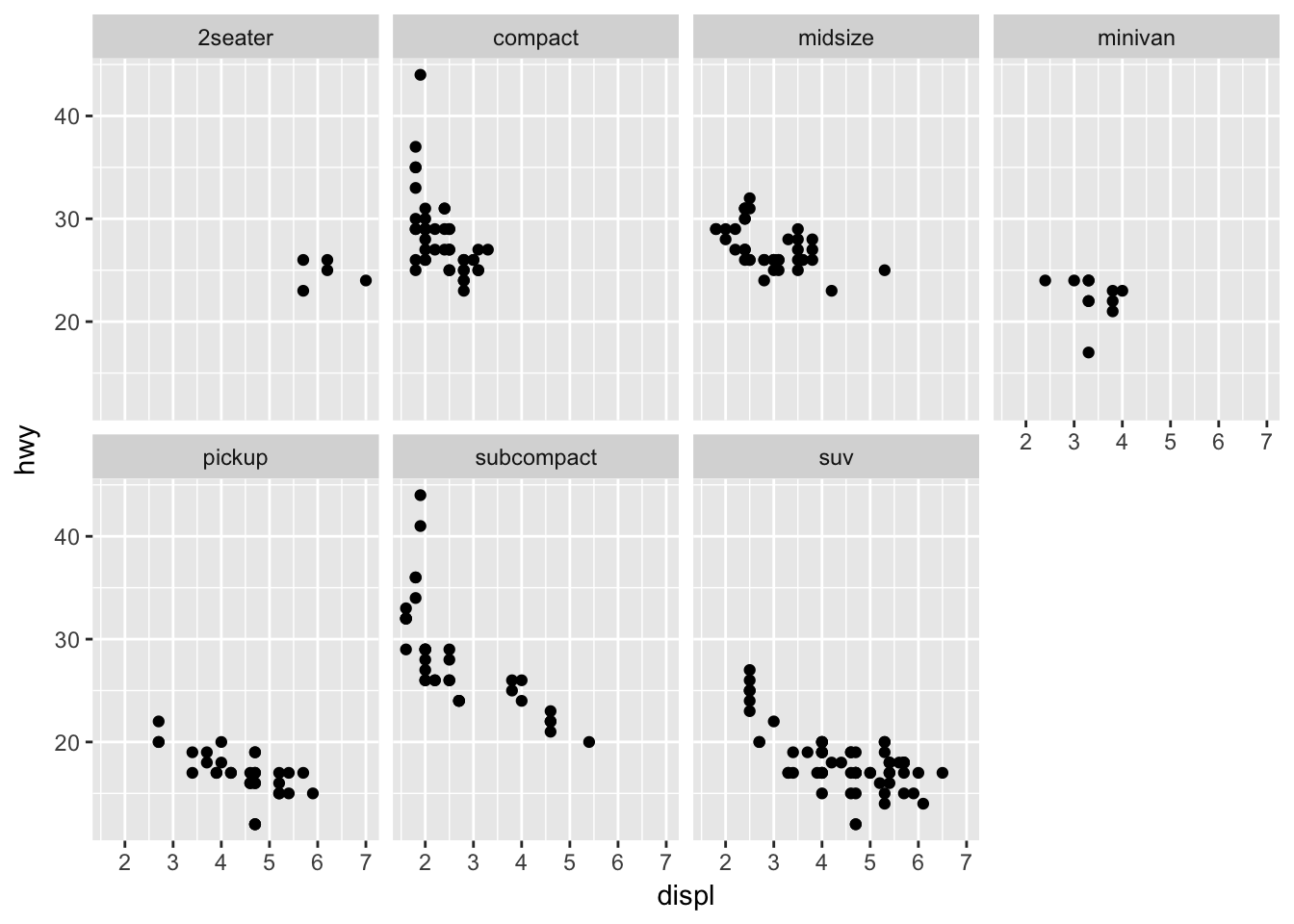
str(diamonds) # a larger dataset## Classes 'tbl_df', 'tbl' and 'data.frame': 53940 obs. of 10 variables:
## $ carat : num 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
## $ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
## $ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
## $ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
## $ depth : num 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
## $ table : num 55 61 65 58 58 57 57 55 61 61 ...
## $ price : int 326 326 327 334 335 336 336 337 337 338 ...
## $ x : num 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
## $ y : num 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
## $ z : num 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...# helps to break up data into sub-groups
ggplot(diamonds, aes(carat, price, color = clarity)) +
geom_point() +
stat_smooth(method = "lm") +
facet_grid(~cut)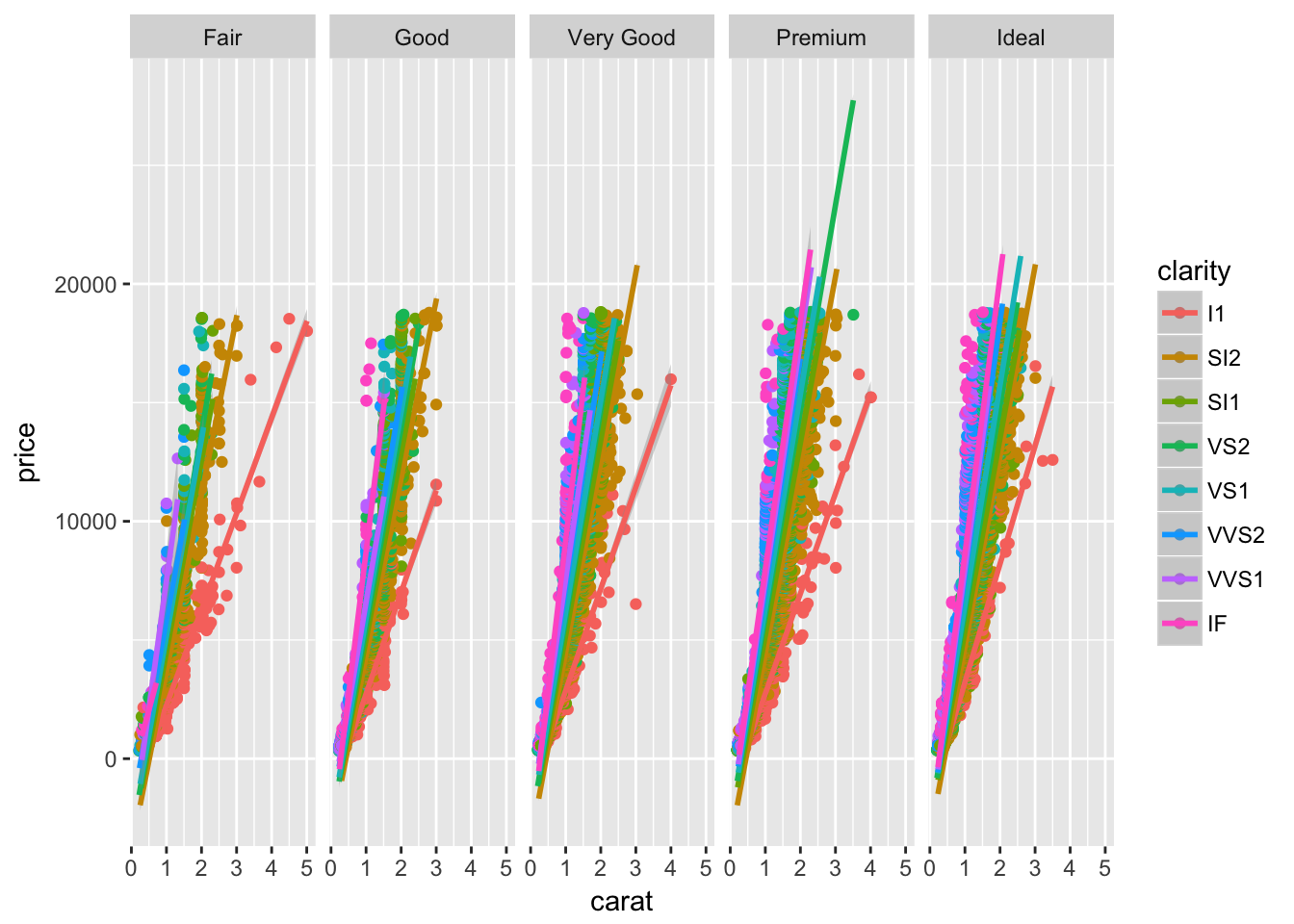
# depends on the trends/comparisons
# acts as another resolution dim- Read
?facet_wrap. What does nrow do? What does the argumentncol =do? What other arguments control the layout of the individual panels? Why doesn’tfacet_grid()have nrow and ncol argument?
?facet_wrap
# build a grid based on number of rows/cols
# allows panels to fill grid by rows or columns too
?facet_grid
# build all possible var combos based on levels of fct/as.factor(chr)
# control order/position with levels(fct) in both3.6 Geoms
- What geom would you use to draw a line chart? A boxplot? A histogram? An area chart?
# eval = F
geom_line()
geom_boxplot()
geom_histogram()
geom_density()
geom_area()- Run this code in your head and predict what the output will look like. Then, run the code in R and check your predictions.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth(se = FALSE)## `geom_smooth()` using method = 'loess'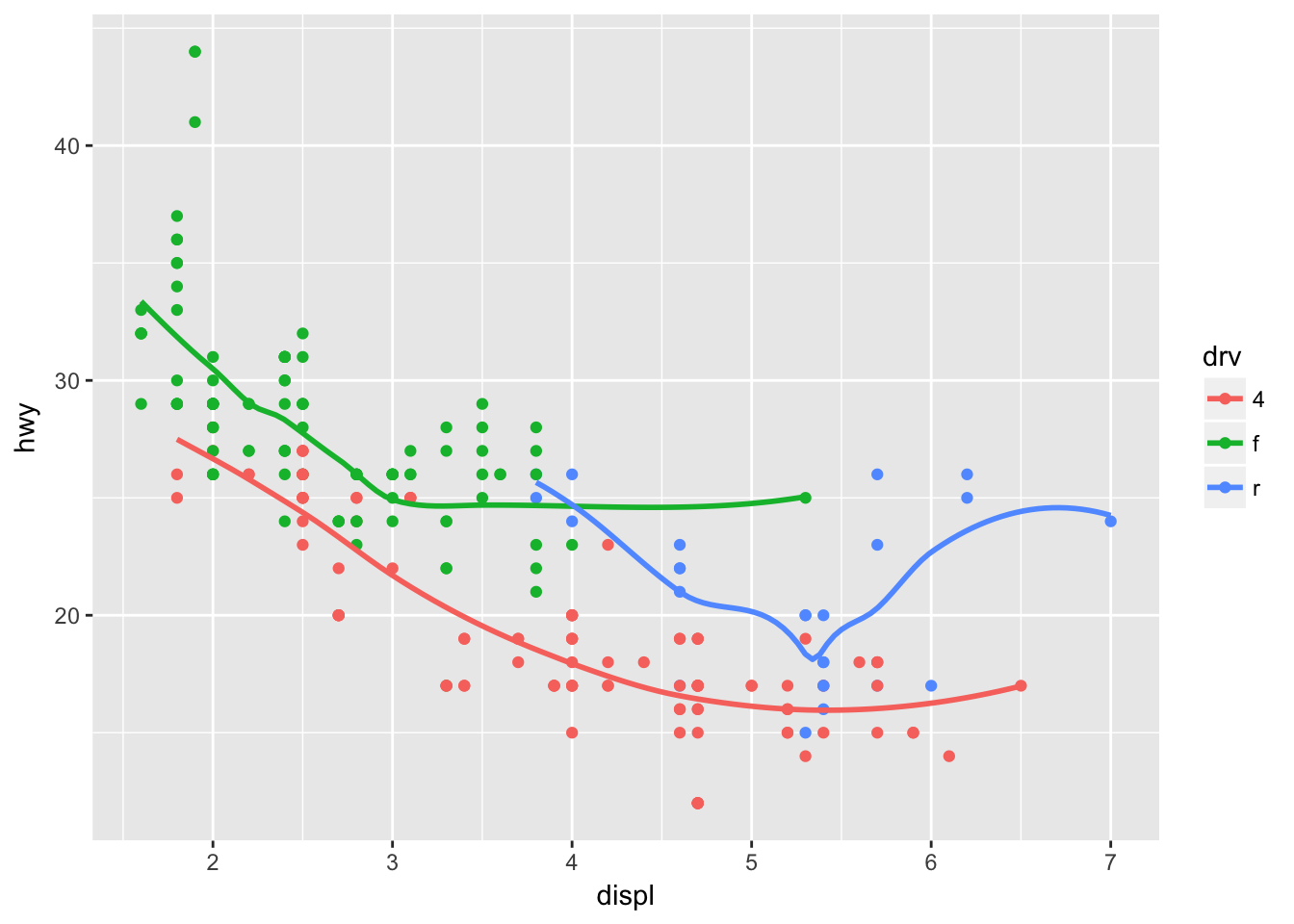
# a scatter plot with a trend smooth
# defaults to loess (Localy weighted polynomial regression)3a. What does show.legend = FALSE do? What happens if you remove it?
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth(show.legend = F)## `geom_smooth()` using method = 'loess'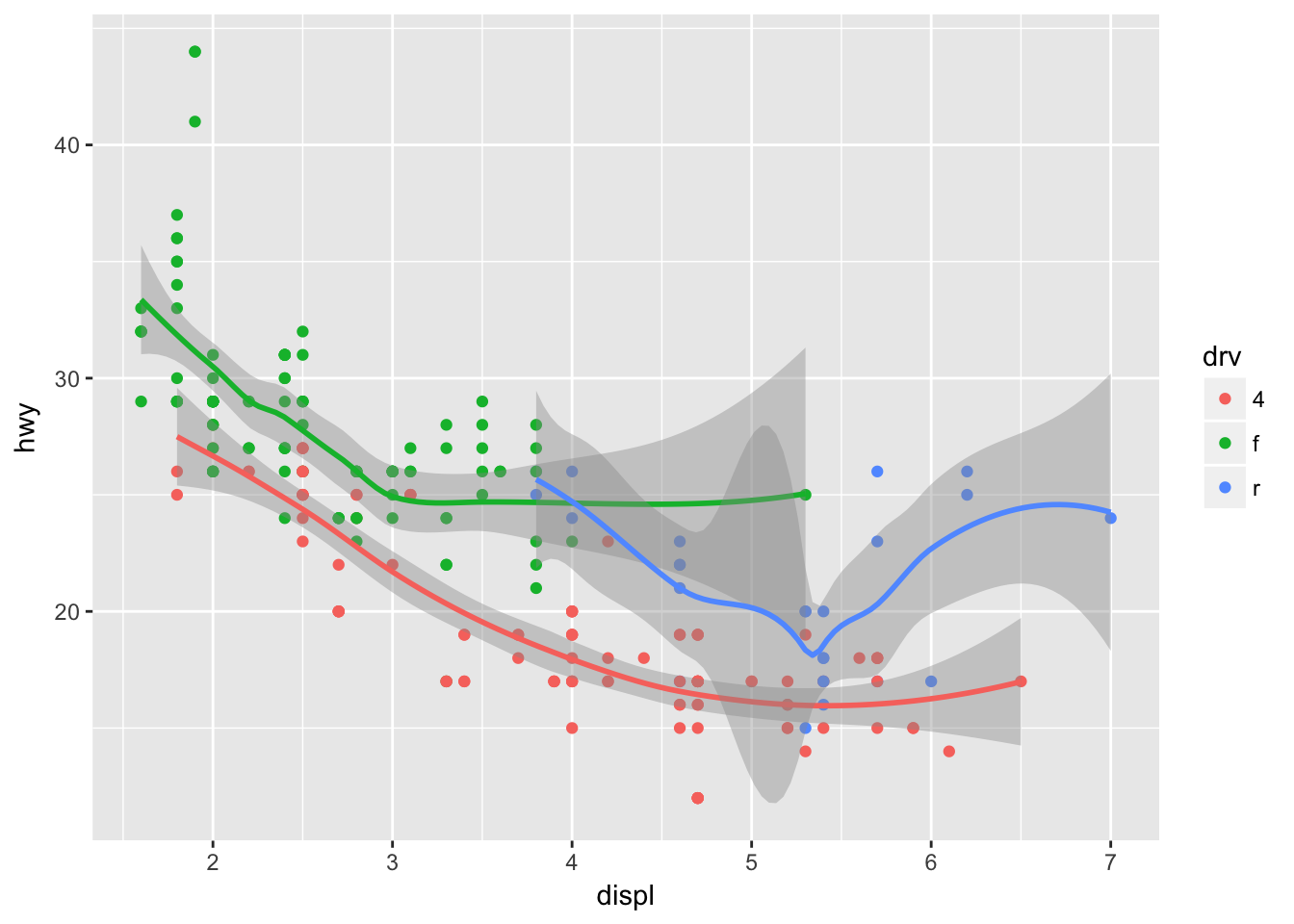
# removes legend for a specific layer
# avoid/make confustion?3b. Why do you think I used it earlier in the chapter?
#to avoid visual confustion? tricky example?- What does the se argument to geom_smooth() do?
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth() # shows a confidence interval, .95 default## `geom_smooth()` using method = 'loess'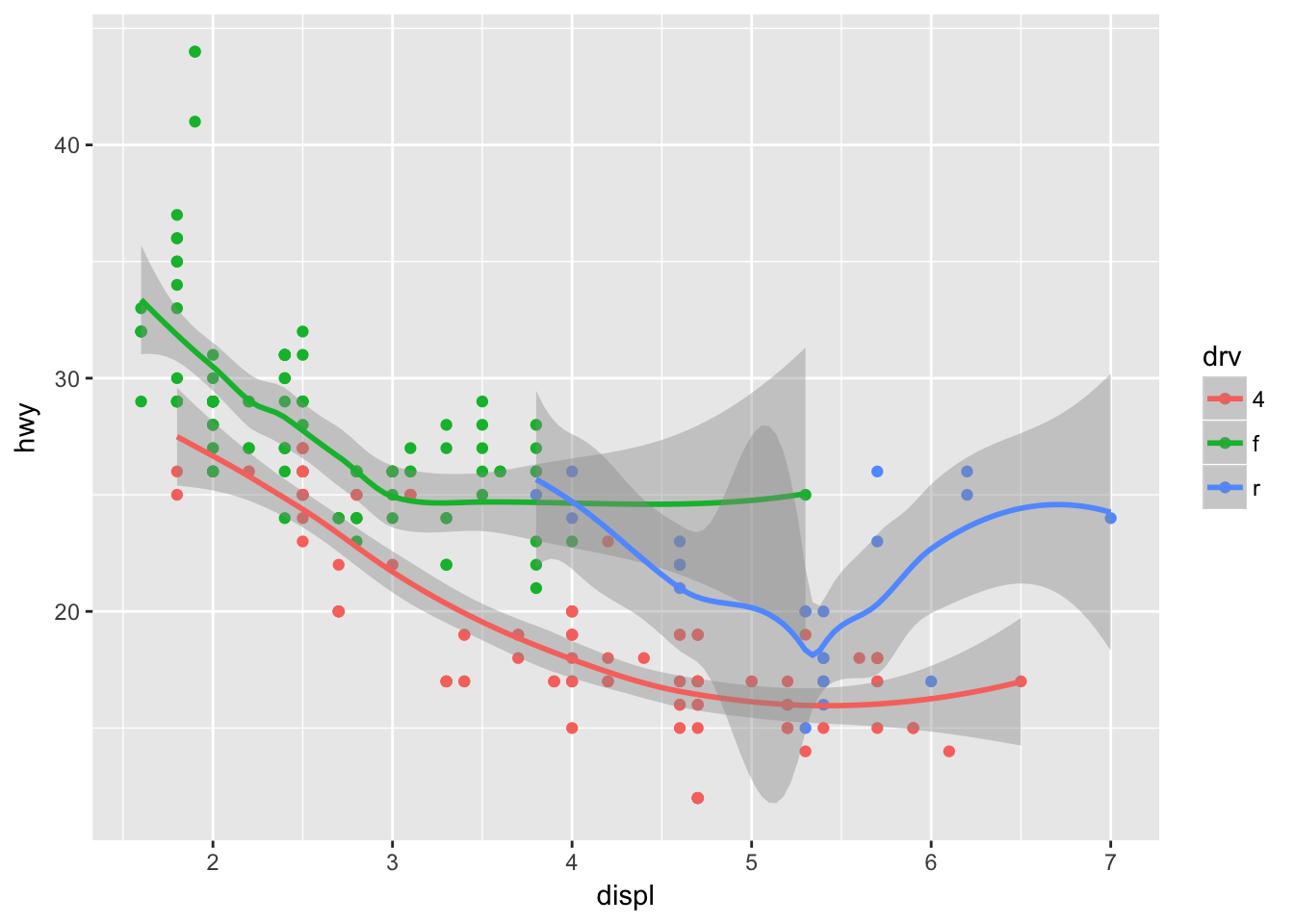
Will these two graphs look different? Why/why not?
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = cyl, group = cyl)) +
geom_point() +
geom_smooth()## `geom_smooth()` using method = 'loess'
ggplot() +
geom_point(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_smooth(data = mpg, mapping = aes(x = displ, y = hwy))## `geom_smooth()` using method = 'loess'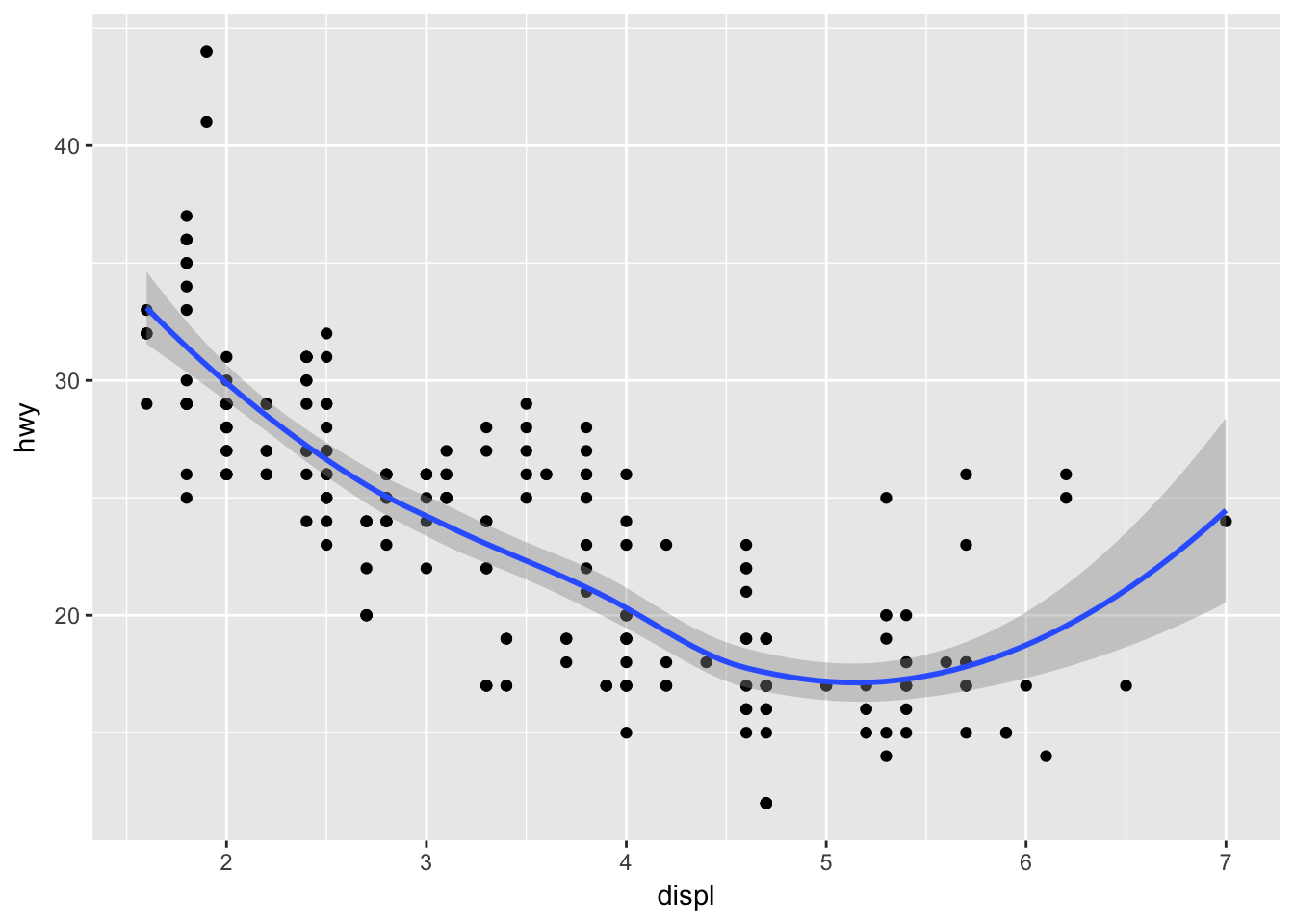
# no, every sub-layer tries to inherit from the top layer, unless "inherit.aes = F"- Recreate the R code necessary to generate the following graphs.
# try to change/add one argument per interation
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_smooth(se = F)## `geom_smooth()` using method = 'loess'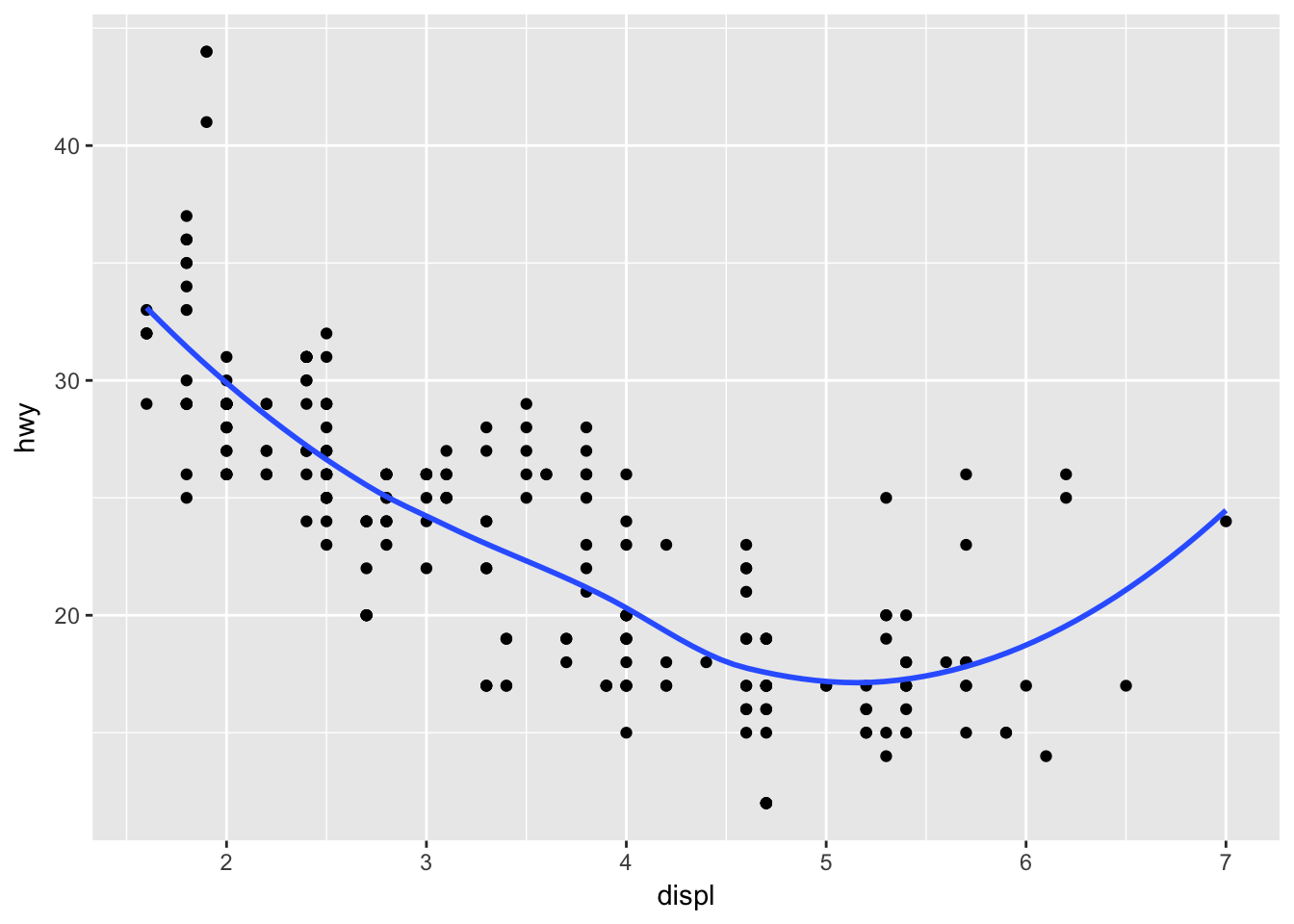
ggplot(mpg, aes(displ, hwy, group = drv)) + # establish a grouping var
geom_point() +
stat_smooth(se = F)## `geom_smooth()` using method = 'loess'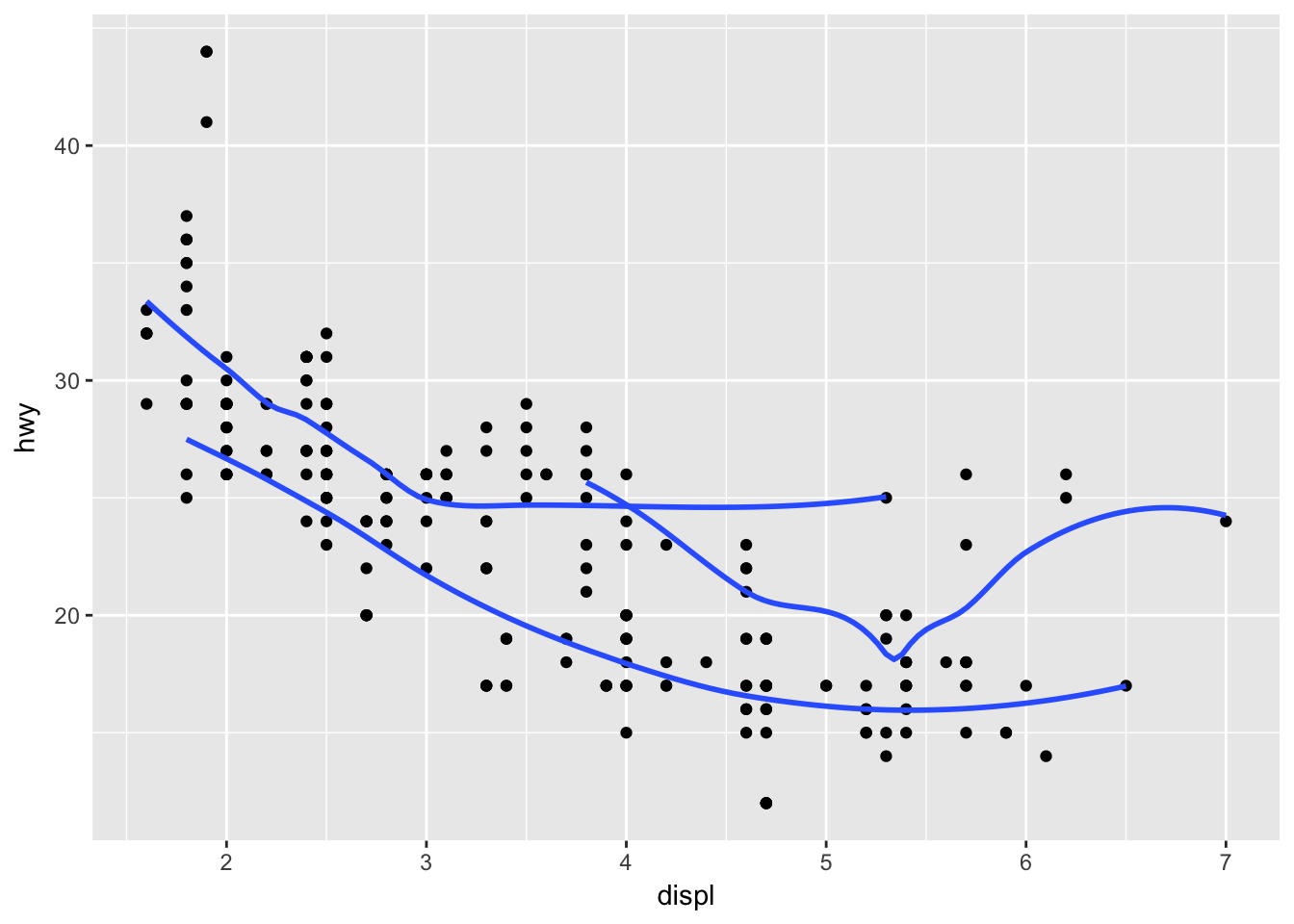
ggplot(mpg, aes(displ, hwy, color = drv)) + # color var does grouping by default
geom_point() +
stat_smooth(se = F)## `geom_smooth()` using method = 'loess'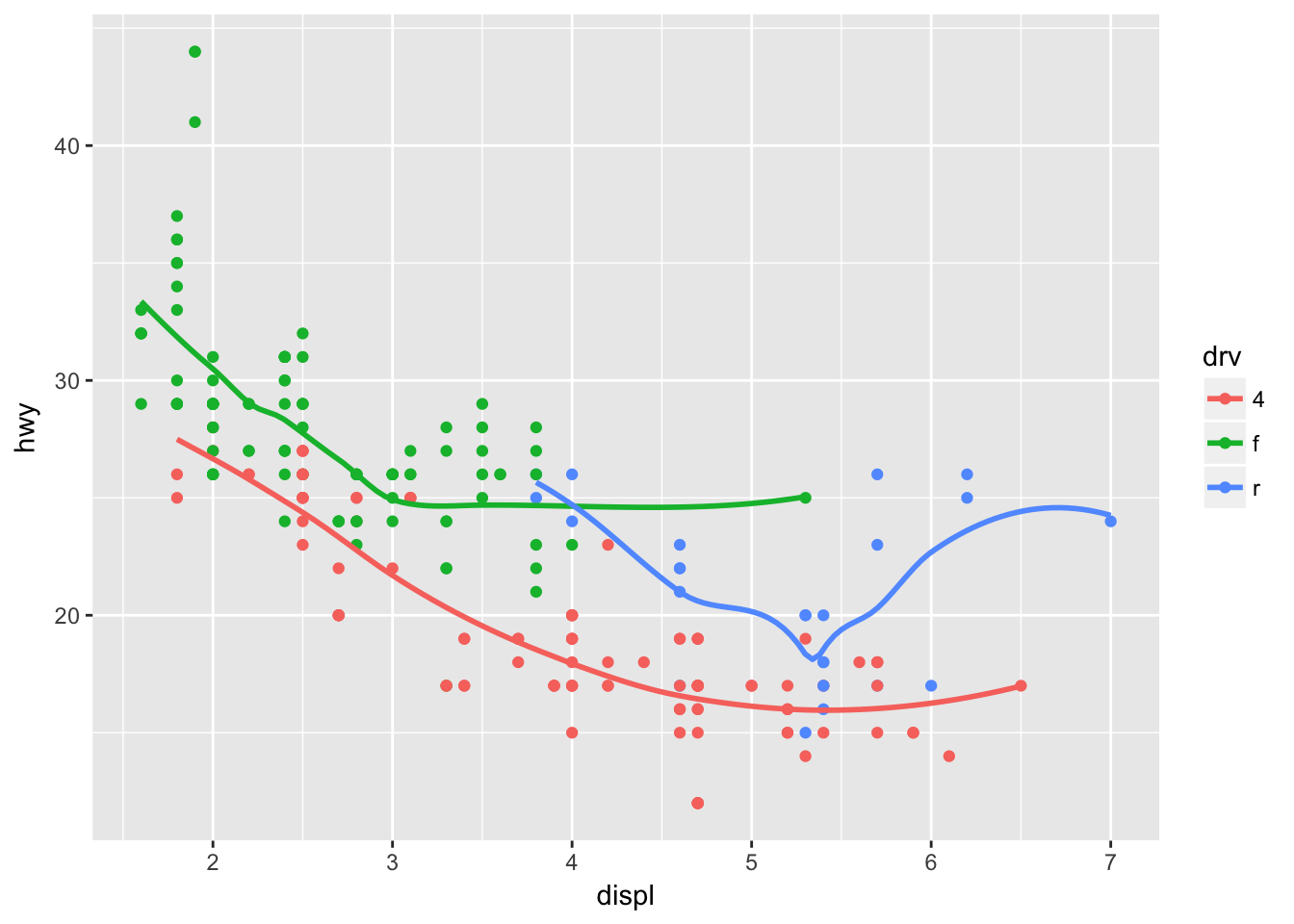
ggplot(mpg, aes(displ, hwy, color = drv)) +
geom_point() +
stat_smooth(aes(color = NULL), se = F) # turn off color group for this layer## `geom_smooth()` using method = 'loess'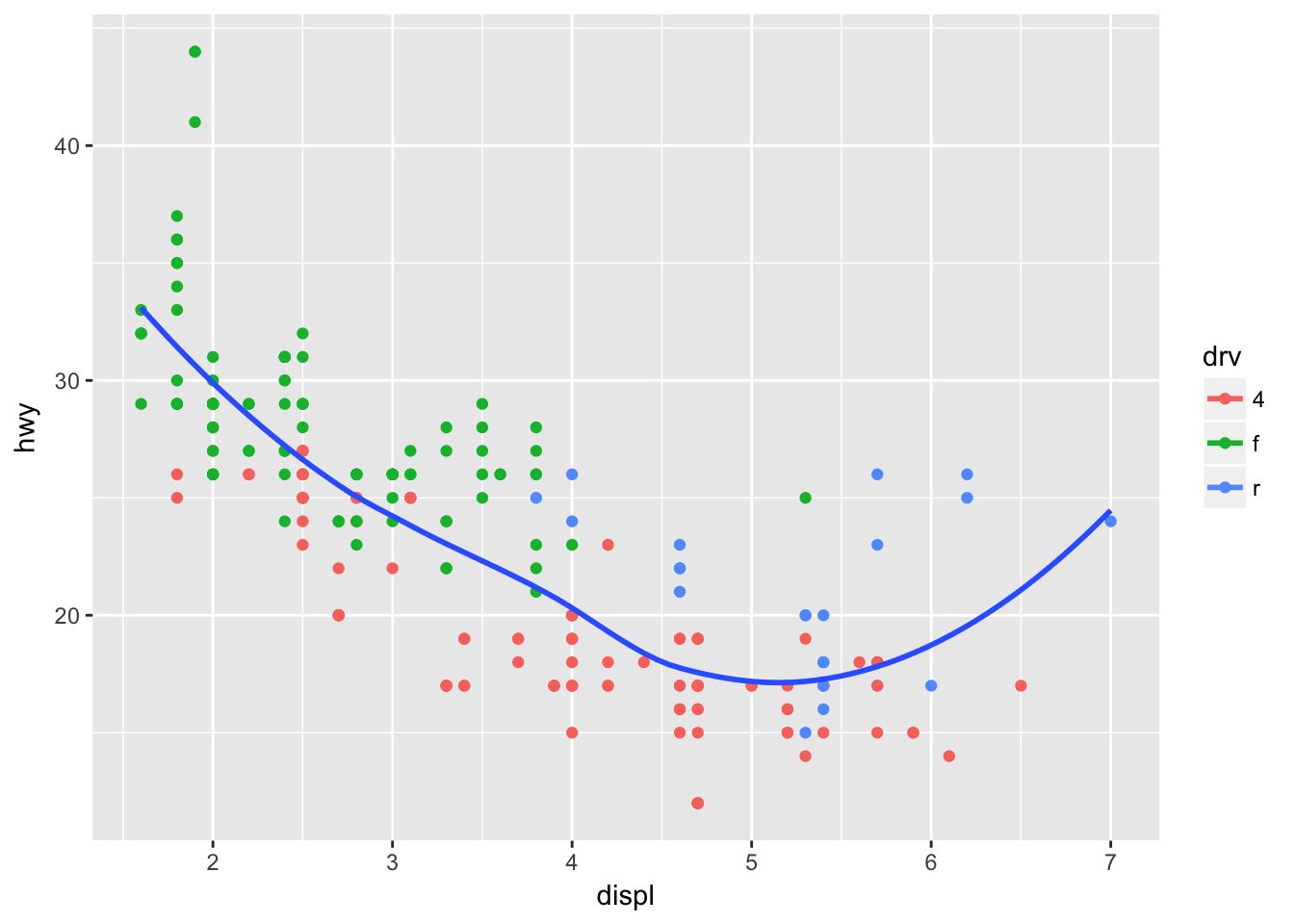
ggplot(mpg, aes(displ, hwy, color = drv)) +
geom_point() +
stat_smooth(aes(color = NULL, linetype = drv), se = F) # turn on linetype aes for this layer## `geom_smooth()` using method = 'loess'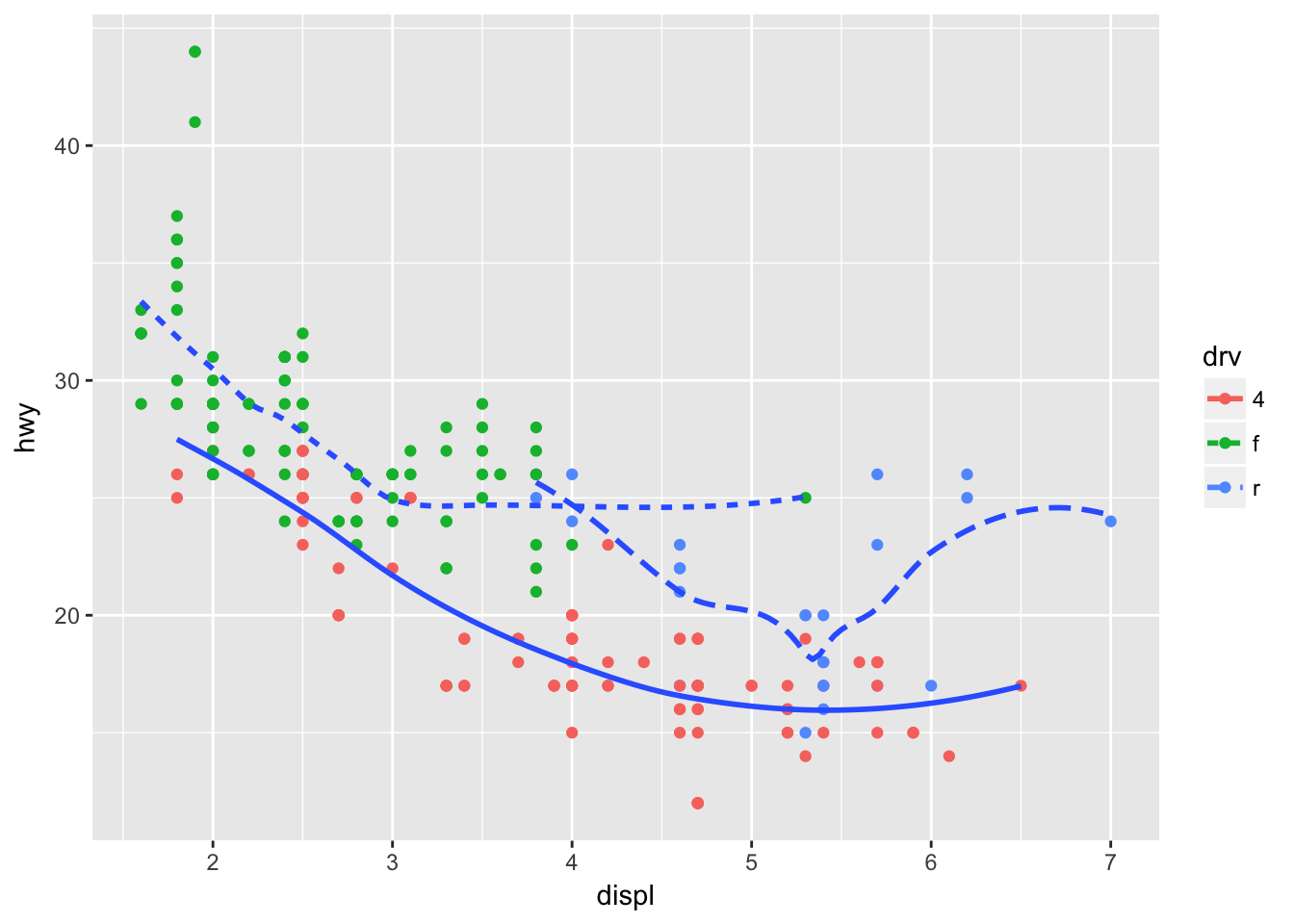
ggplot(mpg, aes(displ, hwy, fill = drv)) +
geom_point(shape = 21, size = 4, stroke = 3, color = "white") +
theme_grey()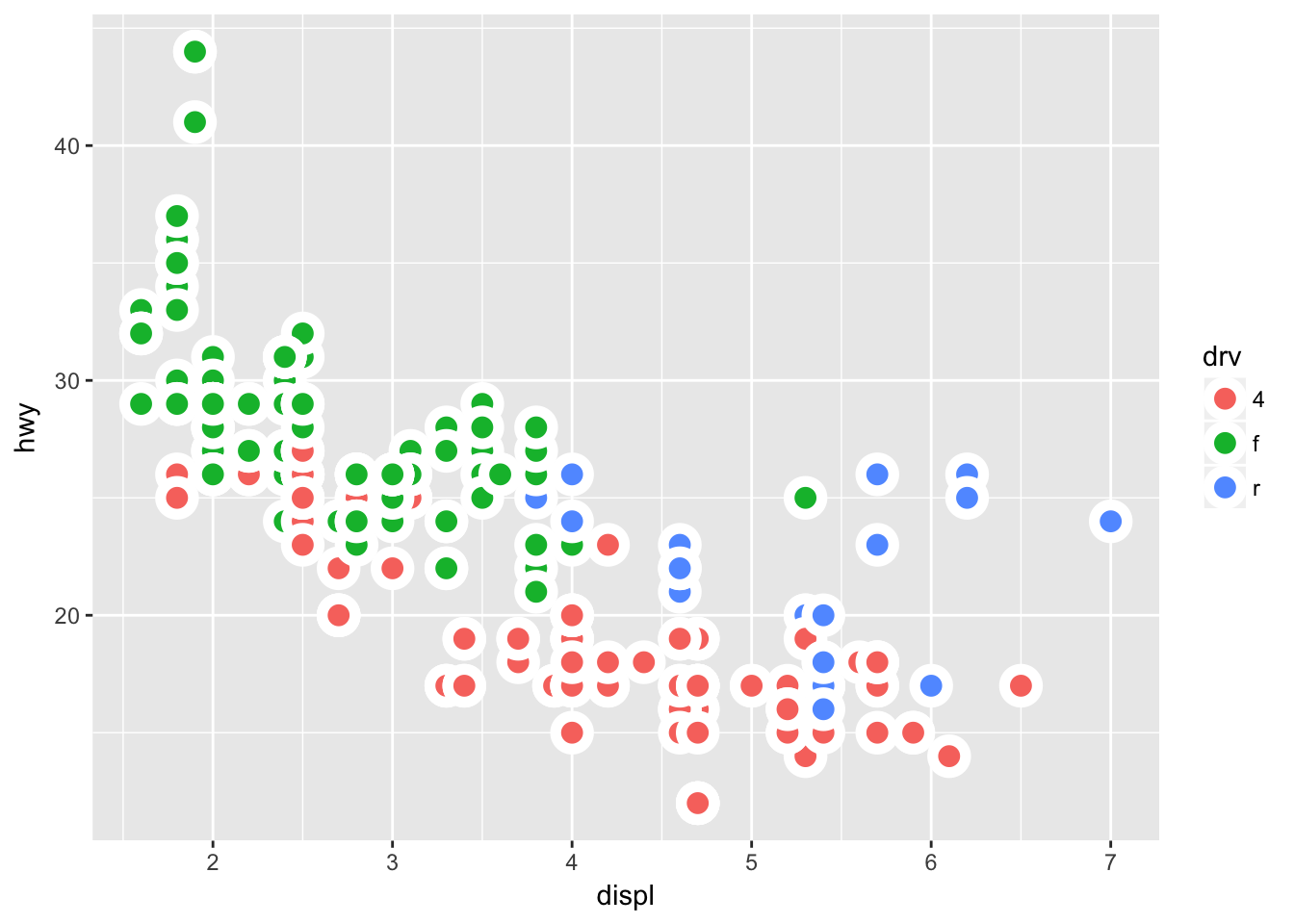
5 Intro to dplyr
5.2 Filter
- Find all flights that:
- Had an arrival delay of two or more hours
library(nycflights13)
flights %>% filter(arr_delay > 120)## # A tibble: 10,034 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 811 630 101 1047
## 2 2013 1 1 848 1835 853 1001
## 3 2013 1 1 957 733 144 1056
## 4 2013 1 1 1114 900 134 1447
## 5 2013 1 1 1505 1310 115 1638
## 6 2013 1 1 1525 1340 105 1831
## 7 2013 1 1 1549 1445 64 1912
## 8 2013 1 1 1558 1359 119 1718
## 9 2013 1 1 1732 1630 62 2028
## 10 2013 1 1 1803 1620 103 2008
## # ... with 10,024 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Flew to Houston (IAH or HOU)
flights %>% filter(dest %in% c("IAH", "HOU"))## # A tibble: 9,313 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 623 627 -4 933
## 4 2013 1 1 728 732 -4 1041
## 5 2013 1 1 739 739 0 1104
## 6 2013 1 1 908 908 0 1228
## 7 2013 1 1 1028 1026 2 1350
## 8 2013 1 1 1044 1045 -1 1352
## 9 2013 1 1 1114 900 134 1447
## 10 2013 1 1 1205 1200 5 1503
## # ... with 9,303 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Were operated by United, American, or Delta
flights %>% filter(carrier %in% c("AA", "UA", "DL"))## # A tibble: 139,504 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 554 600 -6 812
## 5 2013 1 1 554 558 -4 740
## 6 2013 1 1 558 600 -2 753
## 7 2013 1 1 558 600 -2 924
## 8 2013 1 1 558 600 -2 923
## 9 2013 1 1 559 600 -1 941
## 10 2013 1 1 559 600 -1 854
## # ... with 139,494 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Departed in summer (July, August, and September)
flights %>% filter(month %in% 7:9)## # A tibble: 86,326 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 7 1 1 2029 212 236
## 2 2013 7 1 2 2359 3 344
## 3 2013 7 1 29 2245 104 151
## 4 2013 7 1 43 2130 193 322
## 5 2013 7 1 44 2150 174 300
## 6 2013 7 1 46 2051 235 304
## 7 2013 7 1 48 2001 287 308
## 8 2013 7 1 58 2155 183 335
## 9 2013 7 1 100 2146 194 327
## 10 2013 7 1 100 2245 135 337
## # ... with 86,316 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Arrived more than two hours late, but didn’t leave late
flights %>% filter(arr_delay > 120, dep_delay <= 0)## # A tibble: 29 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 27 1419 1420 -1 1754
## 2 2013 10 7 1350 1350 0 1736
## 3 2013 10 7 1357 1359 -2 1858
## 4 2013 10 16 657 700 -3 1258
## 5 2013 11 1 658 700 -2 1329
## 6 2013 3 18 1844 1847 -3 39
## 7 2013 4 17 1635 1640 -5 2049
## 8 2013 4 18 558 600 -2 1149
## 9 2013 4 18 655 700 -5 1213
## 10 2013 5 22 1827 1830 -3 2217
## # ... with 19 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Were delayed by at least an hour, but made up over 30 minutes in flight
flights %>% filter(dep_delay > 60, arr_delay < (dep_delay - 30))## # A tibble: 1,819 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 2205 1720 285 46
## 2 2013 1 1 2326 2130 116 131
## 3 2013 1 3 1503 1221 162 1803
## 4 2013 1 3 1839 1700 99 2056
## 5 2013 1 3 1850 1745 65 2148
## 6 2013 1 3 1941 1759 102 2246
## 7 2013 1 3 1950 1845 65 2228
## 8 2013 1 3 2257 2000 177 45
## 9 2013 1 4 1917 1700 137 2135
## 10 2013 1 4 2010 1745 145 2257
## # ... with 1,809 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Departed between midnight and 6am (inclusive)
flights %>% filter(dep_time %in% 0:600)## # A tibble: 9,344 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 9,334 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Another useful dplyr filtering helper is between(). What does it do? Can you use it to simplify the code needed to answer the previous challenges?
I don’t think using between() is an advantage over using %in% operator
flights %>% filter(dep_time %in% 0:600)## # A tibble: 9,344 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 9,334 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm># vs
flights %>% filter(between(dep_time, 0, 600))## # A tibble: 9,344 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 9,334 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- How many flights have a missing dep_time? What other variables are missing? What might these rows represent?
flights %>% filter(is.na(dep_time)) %>% nrow()## [1] 8255flights %>% filter(is.na(dep_time)) %>% map(~ sum(is.na(.))) # look for mostly na columns## $year
## [1] 0
##
## $month
## [1] 0
##
## $day
## [1] 0
##
## $dep_time
## [1] 8255
##
## $sched_dep_time
## [1] 0
##
## $dep_delay
## [1] 8255
##
## $arr_time
## [1] 8255
##
## $sched_arr_time
## [1] 0
##
## $arr_delay
## [1] 8255
##
## $carrier
## [1] 0
##
## $flight
## [1] 0
##
## $tailnum
## [1] 2512
##
## $origin
## [1] 0
##
## $dest
## [1] 0
##
## $air_time
## [1] 8255
##
## $distance
## [1] 0
##
## $hour
## [1] 0
##
## $minute
## [1] 0
##
## $time_hour
## [1] 0flights %>% filter(is.na(dep_time))## # A tibble: 8,255 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 NA 1630 NA NA
## 2 2013 1 1 NA 1935 NA NA
## 3 2013 1 1 NA 1500 NA NA
## 4 2013 1 1 NA 600 NA NA
## 5 2013 1 2 NA 1540 NA NA
## 6 2013 1 2 NA 1620 NA NA
## 7 2013 1 2 NA 1355 NA NA
## 8 2013 1 2 NA 1420 NA NA
## 9 2013 1 2 NA 1321 NA NA
## 10 2013 1 2 NA 1545 NA NA
## # ... with 8,245 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>colSums(is.na(flights))## year month day dep_time sched_dep_time
## 0 0 0 8255 0
## dep_delay arr_time sched_arr_time arr_delay carrier
## 8255 8713 0 9430 0
## flight tailnum origin dest air_time
## 0 2512 0 0 9430
## distance hour minute time_hour
## 0 0 0 0Departure delay, arrival time, arrival delay and airtime are all missing in these flight records. Perhaps all of these flights were canceled.
- Why is NA ^ 0 not missing? Why is NA | TRUE not missing? Why is FALSE & NA not missing? Can you figure out the general rule? (NA * 0 is a tricky counterexample!)
NA refers to an unknown value. Depending on the operation, results will vary:
# NA represent a number (-Inf:Inf)
NA^0 # all numbers raised to 0 are 1## [1] 1# NA represents a logical ( so either TRUE or FALSE )
NA | TRUE # regardless of NA, one TRUE in an `or` operator returns TRUE## [1] TRUEFALSE & NA # one FALSE in an `and` operator returns FALSE## [1] FALSENA * 0 # Inf * 0 = Inf## [1] NA5.3 Arrange
- How could you use arrange() to sort all missing values to the start? (Hint: use
is.na()).
flights %>% arrange(-is.na(dep_time))## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 NA 1630 NA NA
## 2 2013 1 1 NA 1935 NA NA
## 3 2013 1 1 NA 1500 NA NA
## 4 2013 1 1 NA 600 NA NA
## 5 2013 1 2 NA 1540 NA NA
## 6 2013 1 2 NA 1620 NA NA
## 7 2013 1 2 NA 1355 NA NA
## 8 2013 1 2 NA 1420 NA NA
## 9 2013 1 2 NA 1321 NA NA
## 10 2013 1 2 NA 1545 NA NA
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Sort flights to find the most delayed flights. Find the flights that left earliest.
flights %>% arrange(-dep_delay) # most delayed## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 9 641 900 1301 1242
## 2 2013 6 15 1432 1935 1137 1607
## 3 2013 1 10 1121 1635 1126 1239
## 4 2013 9 20 1139 1845 1014 1457
## 5 2013 7 22 845 1600 1005 1044
## 6 2013 4 10 1100 1900 960 1342
## 7 2013 3 17 2321 810 911 135
## 8 2013 6 27 959 1900 899 1236
## 9 2013 7 22 2257 759 898 121
## 10 2013 12 5 756 1700 896 1058
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>flights %>% arrange(dep_delay) # left earliest## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 12 7 2040 2123 -43 40
## 2 2013 2 3 2022 2055 -33 2240
## 3 2013 11 10 1408 1440 -32 1549
## 4 2013 1 11 1900 1930 -30 2233
## 5 2013 1 29 1703 1730 -27 1947
## 6 2013 8 9 729 755 -26 1002
## 7 2013 10 23 1907 1932 -25 2143
## 8 2013 3 30 2030 2055 -25 2213
## 9 2013 3 2 1431 1455 -24 1601
## 10 2013 5 5 934 958 -24 1225
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Sort flights to find the fastest flights.
flights %>% arrange(distance / air_time)## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 28 1917 1825 52 2118
## 2 2013 6 29 755 800 -5 1035
## 3 2013 8 28 932 940 -8 1116
## 4 2013 1 30 1037 955 42 1221
## 5 2013 11 27 556 600 -4 727
## 6 2013 5 21 558 600 -2 721
## 7 2013 12 9 1540 1535 5 1720
## 8 2013 6 10 1356 1300 56 1646
## 9 2013 7 28 1322 1325 -3 1612
## 10 2013 4 11 1349 1345 4 1542
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>flights %>% mutate(speed = distance / air_time) %>% arrange(speed)## # A tibble: 336,776 x 20
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 28 1917 1825 52 2118
## 2 2013 6 29 755 800 -5 1035
## 3 2013 8 28 932 940 -8 1116
## 4 2013 1 30 1037 955 42 1221
## 5 2013 11 27 556 600 -4 727
## 6 2013 5 21 558 600 -2 721
## 7 2013 12 9 1540 1535 5 1720
## 8 2013 6 10 1356 1300 56 1646
## 9 2013 7 28 1322 1325 -3 1612
## 10 2013 4 11 1349 1345 4 1542
## # ... with 336,766 more rows, and 13 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>, speed <dbl>- Which flights travelled the longest? Which travelled the shortest?
sorted <- flights %>% arrange(-distance)
sorted[2]## # A tibble: 336,776 x 1
## month
## <int>
## 1 1
## 2 1
## 3 1
## 4 1
## 5 1
## 6 1
## 7 1
## 8 1
## 9 1
## 10 1
## # ... with 336,766 more rowsslice(sorted, 5)## # A tibble: 1 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 5 858 900 -2 1519
## # ... with 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm># longest
flights %>% arrange(distance) # shortest## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 7 27 NA 106 NA NA
## 2 2013 1 3 2127 2129 -2 2222
## 3 2013 1 4 1240 1200 40 1333
## 4 2013 1 4 1829 1615 134 1937
## 5 2013 1 4 2128 2129 -1 2218
## 6 2013 1 5 1155 1200 -5 1241
## 7 2013 1 6 2125 2129 -4 2224
## 8 2013 1 7 2124 2129 -5 2212
## 9 2013 1 8 2127 2130 -3 2304
## 10 2013 1 9 2126 2129 -3 2217
## # ... with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>5.4 Select
- Brainstorm as many ways as possible to select dep_time, dep_delay, arr_time, and arr_delay from flights.
flights %>% select(matches("^dep|^arr"))## # A tibble: 336,776 x 4
## dep_time dep_delay arr_time arr_delay
## <int> <dbl> <int> <dbl>
## 1 517 2 830 11
## 2 533 4 850 20
## 3 542 2 923 33
## 4 544 -1 1004 -18
## 5 554 -6 812 -25
## 6 554 -4 740 12
## 7 555 -5 913 19
## 8 557 -3 709 -14
## 9 557 -3 838 -8
## 10 558 -2 753 8
## # ... with 336,766 more rows- What happens if you include the name of a variable multiple times in a select() call?
flights %>% select(arr_time, arr_time)## # A tibble: 336,776 x 1
## arr_time
## <int>
## 1 830
## 2 850
## 3 923
## 4 1004
## 5 812
## 6 740
## 7 913
## 8 709
## 9 838
## 10 753
## # ... with 336,766 more rows- What does the one_of() function do? Why might it be helpful in conjunction with this vector?
vars <- c("year", "month", "day", "dep_delay", "arr_delay")
flights %>% select(one_of(vars)) # selects any matching columns from vars## # A tibble: 336,776 x 5
## year month day dep_delay arr_delay
## <int> <int> <int> <dbl> <dbl>
## 1 2013 1 1 2 11
## 2 2013 1 1 4 20
## 3 2013 1 1 2 33
## 4 2013 1 1 -1 -18
## 5 2013 1 1 -6 -25
## 6 2013 1 1 -4 12
## 7 2013 1 1 -5 19
## 8 2013 1 1 -3 -14
## 9 2013 1 1 -3 -8
## 10 2013 1 1 -2 8
## # ... with 336,766 more rows- Does the result of running the following code surprise you? How do the select helpers deal with case by default? How can you change that default?
select(flights, contains("TIME")) # ignore.case == TRUE is default## # A tibble: 336,776 x 6
## dep_time sched_dep_time arr_time sched_arr_time air_time
## <int> <int> <int> <int> <dbl>
## 1 517 515 830 819 227
## 2 533 529 850 830 227
## 3 542 540 923 850 160
## 4 544 545 1004 1022 183
## 5 554 600 812 837 116
## 6 554 558 740 728 150
## 7 555 600 913 854 158
## 8 557 600 709 723 53
## 9 557 600 838 846 140
## 10 558 600 753 745 138
## # ... with 336,766 more rows, and 1 more variables: time_hour <dttm>select(flights, contains("TIME", ignore.case = FALSE)) # matches nothing## # A tibble: 336,776 x 05.5 Mutate
- Currently dep_time and sched_dep_time are convenient to look at, but hard to compute with because they’re not really continuous numbers. Convert them to a more convenient representation of number of minutes since midnight.
flights %>% transmute(new_dep_time = (dep_time %/% 100)*60 + (dep_time %% 100) )## # A tibble: 336,776 x 1
## new_dep_time
## <dbl>
## 1 317
## 2 333
## 3 342
## 4 344
## 5 354
## 6 354
## 7 355
## 8 357
## 9 357
## 10 358
## # ... with 336,766 more rows- Compare
air_timewitharr_time - dep_time. What do you expect to see? What do you see? What do you need to do to fix it?
flights %>% transmute(air_time, new_diff = arr_time - dep_time)## # A tibble: 336,776 x 2
## air_time new_diff
## <dbl> <int>
## 1 227 313
## 2 227 317
## 3 160 381
## 4 183 460
## 5 116 258
## 6 150 186
## 7 158 358
## 8 53 152
## 9 140 281
## 10 138 195
## # ... with 336,766 more rows# need to convert to minutes first
flights %>% mutate(arr_time = (arr_time %/% 100)*60 + (arr_time %% 100),
dep_time = (dep_time %/% 100)*60 + (dep_time %% 100) ) %>%
transmute(air_time, new_diff = arr_time - dep_time)## # A tibble: 336,776 x 2
## air_time new_diff
## <dbl> <dbl>
## 1 227 193
## 2 227 197
## 3 160 221
## 4 183 260
## 5 116 138
## 6 150 106
## 7 158 198
## 8 53 72
## 9 140 161
## 10 138 115
## # ... with 336,766 more rows# now adjust for tz- Compare dep_time, sched_dep_time, and dep_delay. How would you expect those three numbers to be related?
# dep_time should equal sum(sched_dep_time, dep_delay)
flights %>% rowwise() %>%
transmute(dep_time, sum_dep = sum(sched_dep_time, dep_delay, na.rm = T))## Source: local data frame [336,776 x 2]
## Groups: <by row>
##
## # A tibble: 336,776 x 2
## dep_time sum_dep
## <int> <dbl>
## 1 517 517
## 2 533 533
## 3 542 542
## 4 544 544
## 5 554 594
## 6 554 554
## 7 555 595
## 8 557 597
## 9 557 597
## 10 558 598
## # ... with 336,766 more rows- Find the 10 most delayed flights using a ranking function. How do you want to handle ties? Carefully read the documentation for min_rank().
flights %>% arrange(-dep_delay) %>%
slice(1:10)## # A tibble: 10 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 9 641 900 1301 1242
## 2 2013 6 15 1432 1935 1137 1607
## 3 2013 1 10 1121 1635 1126 1239
## 4 2013 9 20 1139 1845 1014 1457
## 5 2013 7 22 845 1600 1005 1044
## 6 2013 4 10 1100 1900 960 1342
## 7 2013 3 17 2321 810 911 135
## 8 2013 6 27 959 1900 899 1236
## 9 2013 7 22 2257 759 898 121
## 10 2013 12 5 756 1700 896 1058
## # ... with 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm>flights %>% top_n(10, dep_delay)## # A tibble: 10 x 19
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 9 641 900 1301 1242
## 2 2013 1 10 1121 1635 1126 1239
## 3 2013 12 5 756 1700 896 1058
## 4 2013 3 17 2321 810 911 135
## 5 2013 4 10 1100 1900 960 1342
## 6 2013 6 15 1432 1935 1137 1607
## 7 2013 6 27 959 1900 899 1236
## 8 2013 7 22 845 1600 1005 1044
## 9 2013 7 22 2257 759 898 121
## 10 2013 9 20 1139 1845 1014 1457
## # ... with 12 more variables: sched_arr_time <int>, arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm>- What does 1:3 + 1:10 return? Why? R will attempt to “recycle” the shorter of the two lists until all of the values in the longer list have been evaluated. If the shorter this is not a multiple of the longer, then a warning will be raised.
1:3 + 1:10 # warning## Warning in 1:3 + 1:10: longer object length is not a multiple of shorter
## object length## [1] 2 4 6 5 7 9 8 10 12 111:10 + 1:2 # no warning## [1] 2 4 4 6 6 8 8 10 10 121:10 + 5 # no warning## [1] 6 7 8 9 10 11 12 13 14 15What trigonometric functions does R provide?
?sin # a lot of them5.6 Summarise
Useful objects from section 5.6 for exercises:
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
cancelled <- filter(flights, is.na(air_time))- Brainstorm at least 5 different ways to assess the typical delay characteristics of a group of flights. Consider the following scenarios:
— 1a. A flight is 15 minutes early 50% of the time, and 15 minutes late 50% of the time.
not_cancelled %>%
# conditional booleans
mutate(early_15 = arr_delay < -15,
late_15 = arr_delay > 15) %>%
group_by(flight) %>%
# sum/count TRUEs and calculate percentage with n() for group counts
summarise( percent_early15 = sum(early_15) / n(),
percent_late15 = sum(late_15) / n() ) %>%
filter(percent_early15 > .5 & percent_late15 > .5) # they don't exist, bc how could it add up to more than 100%## # A tibble: 0 x 3
## # ... with 3 variables: flight <int>, percent_early15 <dbl>,
## # percent_late15 <dbl>— 1b. A flight is always 10 minutes late.
flights %>%
group_by(flight) %>%
summarise(avg_dep_delay = mean(dep_delay)) %>%
filter(avg_dep_delay > 10) %>%
arrange(-avg_dep_delay) # whoa thats ridiculous, a 5 hour average delay!!!## # A tibble: 759 x 2
## flight avg_dep_delay
## <int> <dbl>
## 1 1510 278.0000
## 2 5478 242.0000
## 3 5117 219.0000
## 4 5855 209.0000
## 5 5294 192.0000
## 6 6082 153.0000
## 7 1226 147.0000
## 8 6093 128.0000
## 9 5015 124.0000
## 10 5017 123.3333
## # ... with 749 more rows— 1c. A flight is 30 minutes early 50% of the time, and 30 minutes late 50% of the time.
# this can't happend, see answer 1a for proof/code_template— 1d. 99% of the time a flight is on time. 1% of the time it’s 2 hours late.
(I adjusted question because the original conditionals don’t exist in flights)
— 1d_adj. 90% of the time a flight is on time. 1% of the time it’s 2 hours late.
not_cancelled %>%
# conditional booleans
mutate(on_time = arr_delay <= 0,
late_2hrs= arr_delay >= 120) %>%
group_by(flight) %>%
# sum/count TRUEs and calculate percentage with n() for group counts
summarise( percent_on_time = sum(on_time) / n(),
percent_late_2hrs = sum(late_2hrs) / n() ) %>%
filter(percent_on_time >= .90, percent_late_2hrs > .01) %>%
arrange(-percent_late_2hrs)## # A tibble: 5 x 3
## flight percent_on_time percent_late_2hrs
## <int> <dbl> <dbl>
## 1 1836 0.9000000 0.10000000
## 2 3613 0.9117647 0.02941176
## 3 2174 0.9142857 0.02857143
## 4 5288 0.9268293 0.02439024
## 5 2243 0.9075630 0.01680672- Which is more important: arrival delay or departure delay?
Arrival delay. The reason people fly is to get to a place by a certain time.
- Come up with another approach that will give you the same output as
not_cancelled %>% count(dest)andnot_cancelled %>% count(tailnum, wt = distance)(without usingcount()).
# not_cancelled %>% count(dest)
not_cancelled %>% group_by(dest) %>%
tally()## # A tibble: 104 x 2
## dest n
## <chr> <int>
## 1 ABQ 254
## 2 ACK 264
## 3 ALB 418
## 4 ANC 8
## 5 ATL 16837
## 6 AUS 2411
## 7 AVL 261
## 8 BDL 412
## 9 BGR 358
## 10 BHM 269
## # ... with 94 more rows# not_cancelled %>% count(tailnum, wt = distance)
not_cancelled %>% group_by(tailnum) %>%
summarise(group_distance = sum(distance))## # A tibble: 4,037 x 2
## tailnum group_distance
## <chr> <dbl>
## 1 D942DN 3418
## 2 N0EGMQ 239143
## 3 N10156 109664
## 4 N102UW 25722
## 5 N103US 24619
## 6 N104UW 24616
## 7 N10575 139903
## 8 N105UW 23618
## 9 N107US 21677
## 10 N108UW 32070
## # ... with 4,027 more rows- Our definition of cancelled flights
(is.na(dep_delay) | is.na(arr_delay)) is slightly suboptimal. Why? Which is the most important column?
arr_delay appears to have identical coverage to what I would guess would be the best column/var air_time. So either var covers sufficently…
flights %>%
select(dep_delay, arr_delay, air_time) %>%
map(~ sum(is.na(.)))## $dep_delay
## [1] 8255
##
## $arr_delay
## [1] 9430
##
## $air_time
## [1] 9430- Look at the number of cancelled flights per day. Is there a pattern? Is the proportion of cancelled flights related to the average delay?
# scale the vars (year, month, day) to numeric
cancelled %>%
transmute(time_scale = (month-1)*30 + day) %>% # rough but good enough
ggplot(aes(time_scale)) +
geom_density() +
scale_x_continuous(breaks = seq(1, 360, 30),
labels = seq(1:12)) # crude month markers, but good enough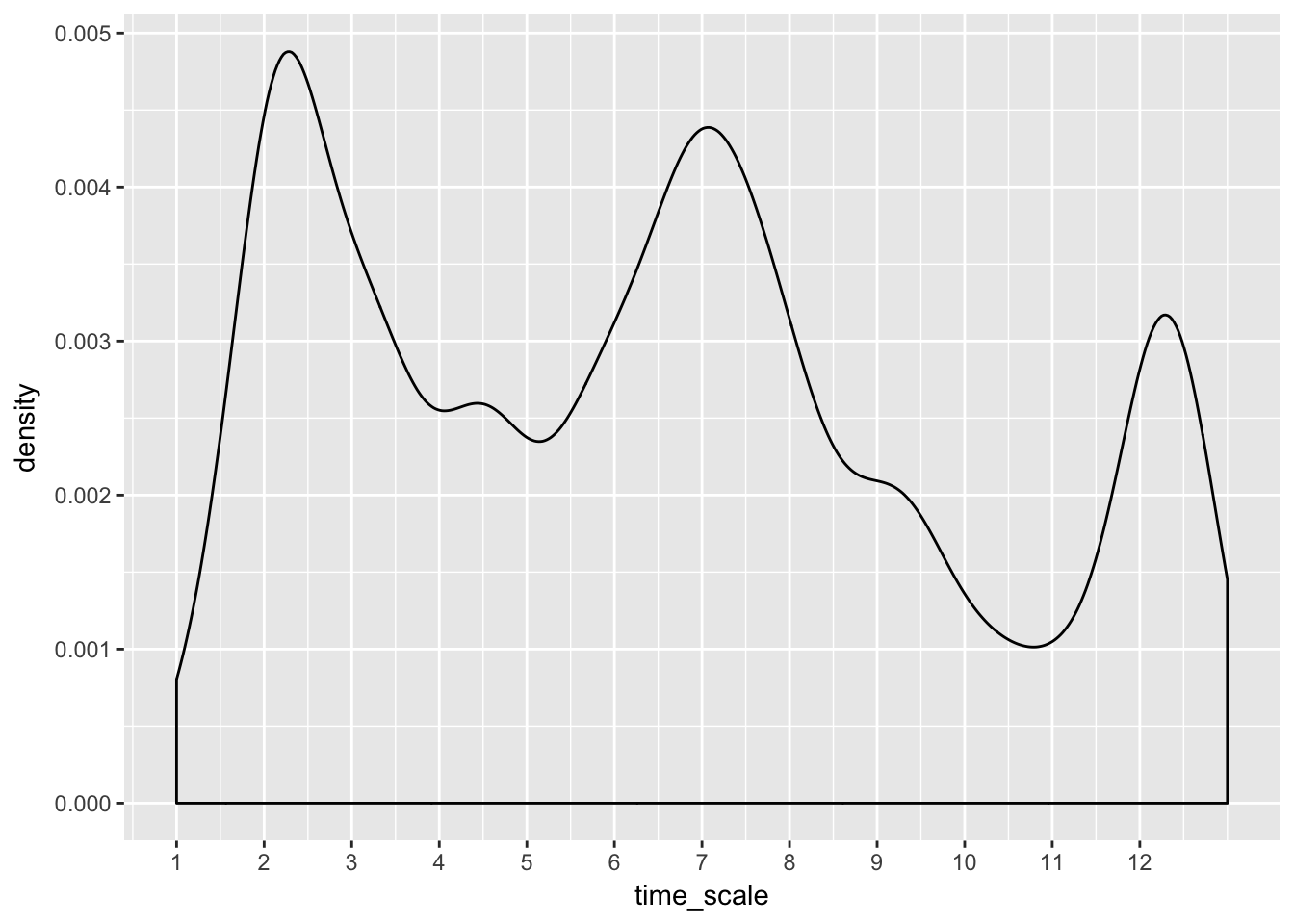
# better built-in fxns exist...?scale_x_datetimeLooks like local maxima are found near major holidays: Valentine’s Day, July 4th and Christmas. I would have guess Thanksgiving would be a big cancel event, maybe if we looked at more data.
flights %>% group_by(month, day) %>%
summarise(prop_canceled = sum(is.na(air_time)) / n(),
avg_dep_delay = mean(dep_delay, na.rm = T)) %>%
mutate(time_scale = (month-1)*30 + day) %>%
ggplot(aes(avg_dep_delay, prop_canceled)) +
geom_point() +
stat_smooth()## `geom_smooth()` using method = 'loess'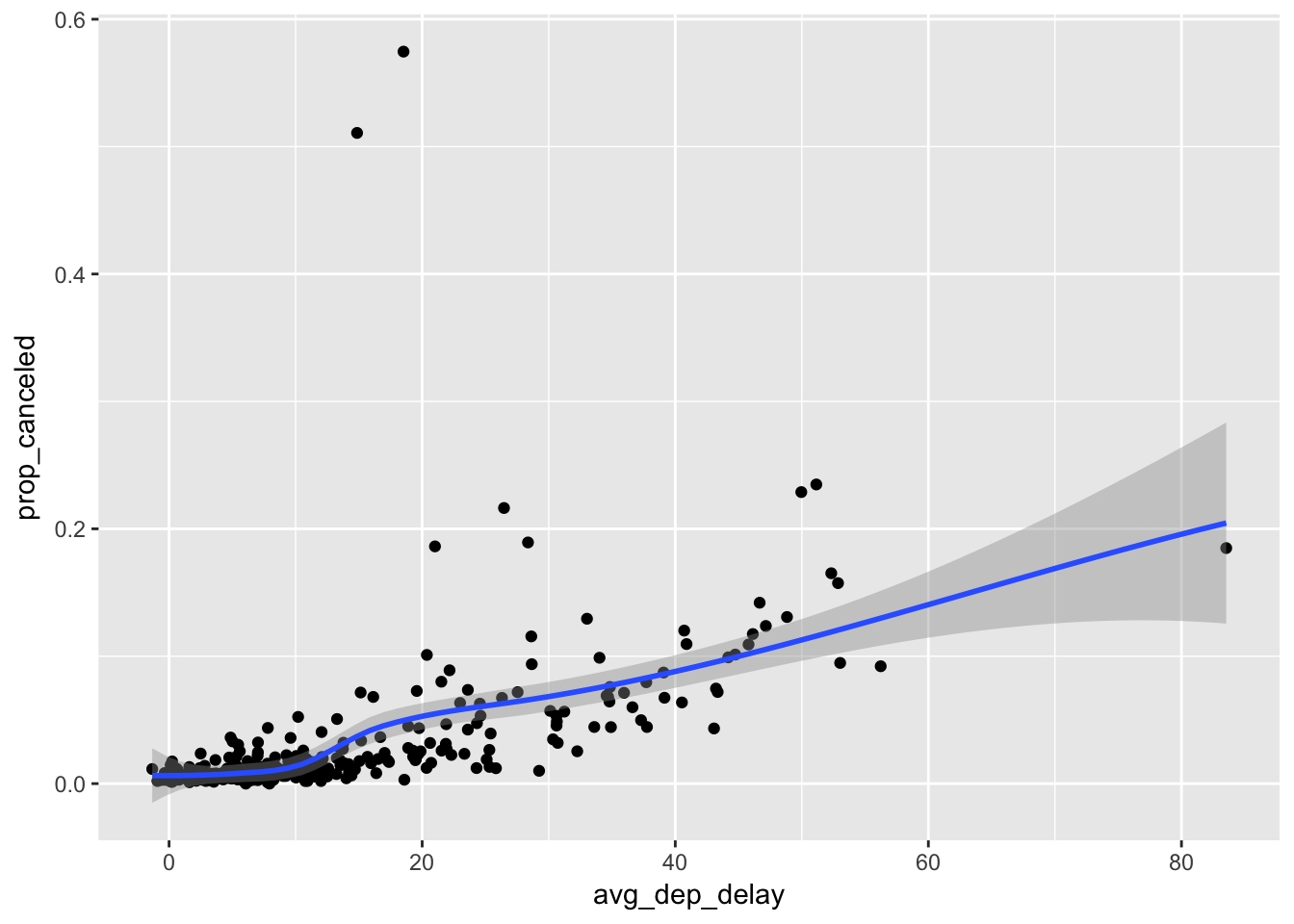
Looks like a weak positive correlation between the average departure delay and the proportional of flights canceled when grouped by day of year.
- Which carrier has the worst delays?
flights %>%
group_by(carrier) %>%
count(wt = dep_delay, sort = T)## # A tibble: 16 x 2
## # Groups: carrier [16]
## carrier n
## <chr> <dbl>
## 1 EV 1024829
## 2 B6 705417
## 3 UA 701898
## 4 DL 442482
## 5 9E 291296
## 6 AA 275551
## 7 MQ 265521
## 8 WN 214011
## 9 US 75168
## 10 VX 66033
## 11 FL 59680
## 12 F9 13787
## 13 YV 10353
## 14 AS 4133
## 15 HA 1676
## 16 OO 365# Express Jet— Challenge: can you disentangle the effects of bad airports vs. bad carriers? Why/why not? (Hint: think about flights %>% group_by(carrier, dest) %>% summarise(n()))
# viz that shiz
not_cancelled %>% group_by(carrier, origin) %>% # using origin to restrict to NYC not the world ;)
count(wt = dep_delay, sort = T) %>%
ggplot(aes(origin, n, fill = carrier)) +
geom_col() +
ggsci::scale_fill_d3("category20")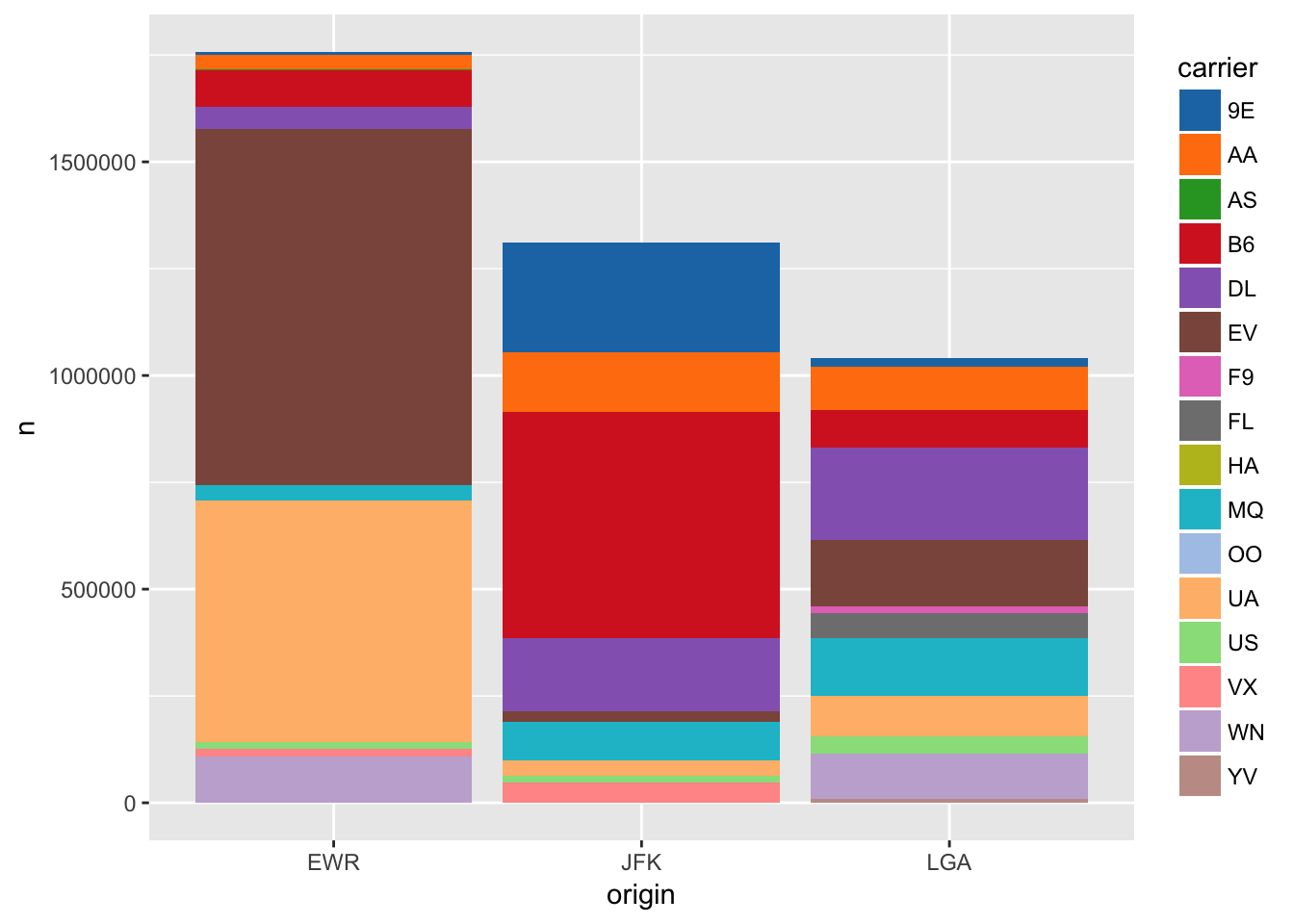
Newark Liberty Internation Airport is the most delayed NYC airport, and it looks like ExpressJet is the worst carrier in terms of total delays across the major airports of NYC.
- What does the sort argument to count() do. When might you use it?
It is short hand for adding %>% arrange(-n).
count(flights, carrier, sort = T)## # A tibble: 16 x 2
## carrier n
## <chr> <int>
## 1 UA 58665
## 2 B6 54635
## 3 EV 54173
## 4 DL 48110
## 5 AA 32729
## 6 MQ 26397
## 7 US 20536
## 8 9E 18460
## 9 WN 12275
## 10 VX 5162
## 11 FL 3260
## 12 AS 714
## 13 F9 685
## 14 YV 601
## 15 HA 342
## 16 OO 32count(flights, carrier) %>%
arrange(-n)## # A tibble: 16 x 2
## carrier n
## <chr> <int>
## 1 UA 58665
## 2 B6 54635
## 3 EV 54173
## 4 DL 48110
## 5 AA 32729
## 6 MQ 26397
## 7 US 20536
## 8 9E 18460
## 9 WN 12275
## 10 VX 5162
## 11 FL 3260
## 12 AS 714
## 13 F9 685
## 14 YV 601
## 15 HA 342
## 16 OO 325.7 Grouped mutate
- Refer back to the lists of useful mutate and filtering functions. Describe how each operation changes when you combine it with grouping.
mutate() will add a new column with the group-wise value. So the new column will have the same length of the data.frame but will have repeated values corresponding to the groups.
flights %>% group_by(flight) %>% mutate(avg_dep_delay = mean(dep_delay))## # A tibble: 336,776 x 20
## # Groups: flight [3,844]
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 600 -6 812
## 6 2013 1 1 554 558 -4 740
## 7 2013 1 1 555 600 -5 913
## 8 2013 1 1 557 600 -3 709
## 9 2013 1 1 557 600 -3 838
## 10 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 13 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>, avg_dep_delay <dbl>filter() will perform the filtering on each group separatly, similar to tapply() where a data.frame is split, an operation is performed on each piece and the data.frame is reconsituted into a whole. So in the case below we will get a smaller data.frame with only the observation of the maximum departure delay for each flight id.
not_cancelled %>% group_by(flight) %>% filter(dep_delay == max(dep_delay))## # A tibble: 3,894 x 19
## # Groups: flight [3,835]
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 559 559 0 702
## 2 2013 1 1 840 845 -5 1053
## 3 2013 1 1 848 1835 853 1001
## 4 2013 1 1 927 930 -3 1231
## 5 2013 1 1 933 935 -2 1120
## 6 2013 1 1 957 733 144 1056
## 7 2013 1 1 1114 900 134 1447
## 8 2013 1 1 1144 1145 -1 1422
## 9 2013 1 1 1327 1329 -2 1624
## 10 2013 1 1 1336 1340 -4 1508
## # ... with 3,884 more rows, and 12 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>- Which plane (tailnum) has the worst on-time record?
not_cancelled %>% group_by(tailnum) %>%
summarise(pct_arr_delay = sum(arr_delay > 0 / n())) %>%
top_n(1, pct_arr_delay)## # A tibble: 1 x 2
## tailnum pct_arr_delay
## <chr> <int>
## 1 N725MQ 215- What time of day should you fly if you want to avoid delays as much as possible?
not_cancelled %>% separate(time_hour, c("date", "time"), sep = " ") %>%
group_by(time) %>%
summarise(avg_dep_delay = mean(dep_delay)) %>%
ggplot(aes(time, avg_dep_delay)) +
geom_col() +
theme(axis.text.x = element_text(angle = 45, vjust = .75, hjust = .75))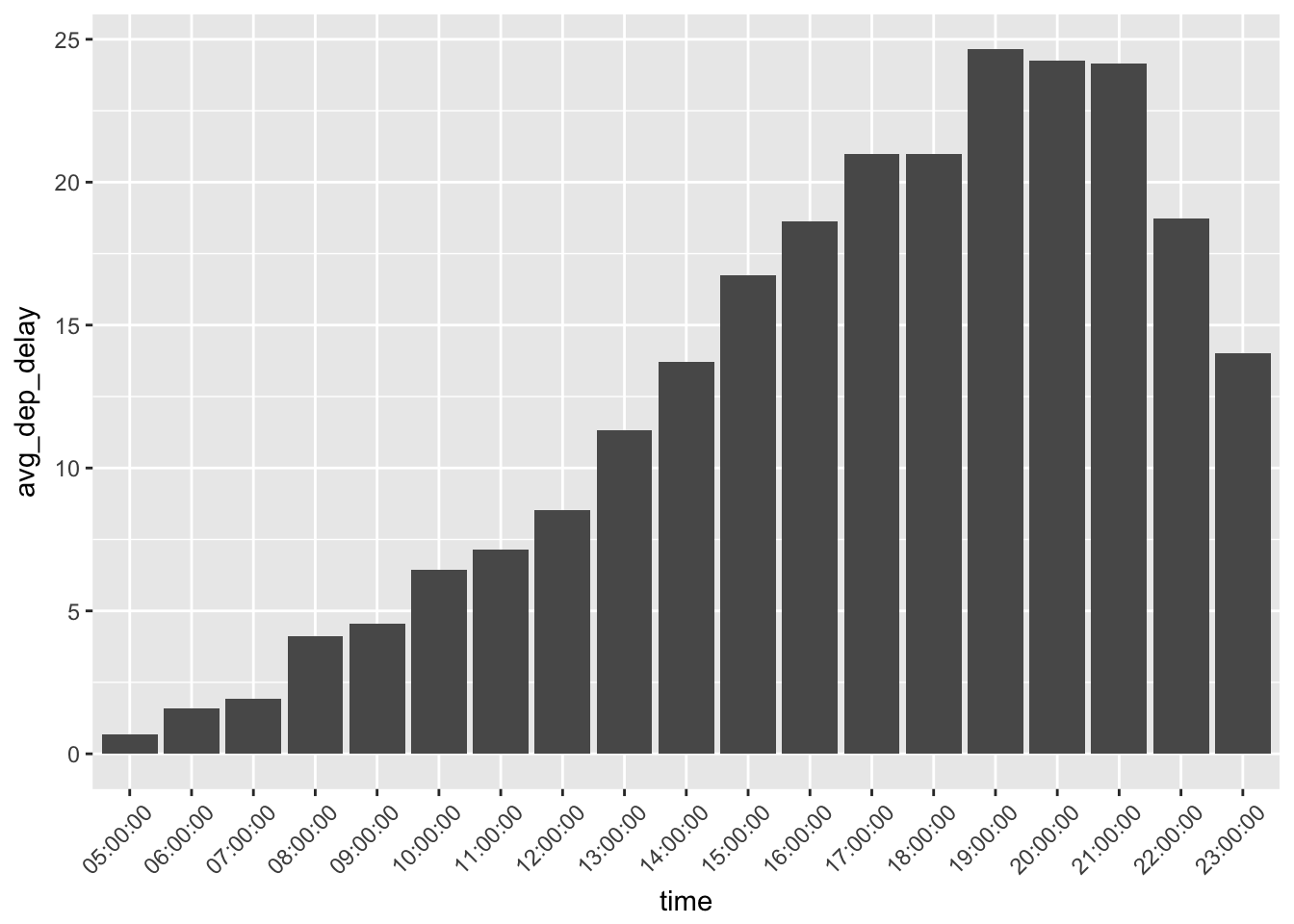
- For each destination, compute the total minutes of delay. For each, flight, compute the proportion of the total delay for its destination.
not_cancelled %>% group_by(dest) %>%
summarise(total_delay = sum(dep_delay),
avg_delay = mean(dep_delay)) %>%
arrange(-total_delay)## # A tibble: 104 x 3
## dest total_delay avg_delay
## <chr> <dbl> <dbl>
## 1 ORD 222528 13.432814
## 2 ATL 209202 12.425135
## 3 SFO 167807 12.738708
## 4 MCO 157343 11.265340
## 5 FLL 150899 12.683786
## 6 LAX 149863 9.351242
## 7 BOS 130121 8.662029
## 8 CLT 125752 9.196431
## 9 DEN 107855 15.044637
## 10 DTW 105821 11.717529
## # ... with 94 more rowsnot_cancelled %>% group_by(dest) %>%
mutate(total_delay = sum(dep_delay)) %>%
group_by(flight, add = T) %>% # by default group_by() ungroups previous groupings, add = TRUE overrides this
summarise(pct_total = sum(dep_delay) / unique(total_delay))## # A tibble: 11,421 x 3
## # Groups: dest [?]
## dest flight pct_total
## <chr> <int> <dbl>
## 1 ABQ 65 0.3550143266
## 2 ABQ 1505 0.6449856734
## 3 ACK 1191 0.3554641598
## 4 ACK 1195 0.0193889542
## 5 ACK 1291 0.1468860165
## 6 ACK 1491 0.4782608696
## 7 ALB 3256 0.0006121824
## 8 ALB 3260 0.0121416182
## 9 ALB 3264 0.0001020304
## 10 ALB 3811 0.0581573309
## # ... with 11,411 more rows- Delays are typically temporally correlated: even once the problem that caused the initial delay has been resolved, later flights are delayed to allow earlier flights to leave. Using lag() explore how the delay of a flight is related to the delay of the immediately preceding flight.
not_cancelled %>% unite(date, month, day) %>%
group_by(origin, date) %>%
filter(n() > 1) %>%
arrange(sched_dep_time) %>%
mutate(delay_lag = lag(dep_delay))## # A tibble: 327,346 x 19
## # Groups: origin, date [1,095]
## year date dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <chr> <int> <int> <dbl> <int> <int>
## 1 2013 1_2 458 500 -2 703 650
## 2 2013 1_3 458 500 -2 650 650
## 3 2013 1_4 456 500 -4 631 650
## 4 2013 1_5 458 500 -2 640 650
## 5 2013 1_6 458 500 -2 718 650
## 6 2013 1_7 454 500 -6 637 648
## 7 2013 1_8 454 500 -6 625 648
## 8 2013 1_9 457 500 -3 647 648
## 9 2013 1_10 450 500 -10 634 648
## 10 2013 1_11 453 500 -7 643 648
## # ... with 327,336 more rows, and 12 more variables: arr_delay <dbl>,
## # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
## # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
## # time_hour <dttm>, delay_lag <dbl>- Look at each destination. Can you find flights that are suspiciously fast? (i.e. flights that represent a potential data entry error). Compute the air time a flight relative to the shortest flight to that destination. Which flights were most delayed in the air?
# super fast
not_cancelled %>% group_by(dest) %>%
mutate(speed = distance / air_time) %>%
arrange(-speed)## # A tibble: 327,346 x 20
## # Groups: dest [104]
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 5 25 1709 1700 9 1923
## 2 2013 7 2 1558 1513 45 1745
## 3 2013 5 13 2040 2025 15 2225
## 4 2013 3 23 1914 1910 4 2045
## 5 2013 1 12 1559 1600 -1 1849
## 6 2013 11 17 650 655 -5 1059
## 7 2013 2 21 2355 2358 -3 412
## 8 2013 11 17 759 800 -1 1212
## 9 2013 11 16 2003 1925 38 17
## 10 2013 11 16 2349 2359 -10 402
## # ... with 327,336 more rows, and 13 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>, speed <dbl># shortest flight per destination
not_cancelled %>% group_by(dest) %>%
filter(air_time == min(air_time)) %>%
select(dest, min_air = air_time) %>%
inner_join(flights, by = "dest") %>%
mutate(relative_air = air_time / min_air) %>%
arrange(-relative_air)## # A tibble: 549,643 x 21
## # Groups: dest [104]
## dest min_air year month day dep_time sched_dep_time dep_delay
## <chr> <dbl> <int> <int> <int> <int> <int> <dbl>
## 1 BOS 21 2013 6 24 1932 1920 12
## 2 BOS 21 2013 6 17 1652 1700 -8
## 3 BOS 21 2013 7 23 1605 1400 125
## 4 BOS 21 2013 7 23 1617 1605 12
## 5 BOS 21 2013 7 23 1242 1237 5
## 6 BOS 21 2013 7 23 1200 1200 0
## 7 BOS 21 2013 2 17 841 840 1
## 8 BOS 21 2013 7 23 1242 1245 -3
## 9 DCA 32 2013 6 10 1356 1300 56
## 10 DCA 32 2013 6 10 1356 1300 56
## # ... with 549,633 more rows, and 13 more variables: arr_time <int>,
## # sched_arr_time <int>, arr_delay <dbl>, carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, air_time <dbl>, distance <dbl>,
## # hour <dbl>, minute <dbl>, time_hour <dttm>, relative_air <dbl>- Find all destinations that are flown by at least two carriers. Use that information to rank the carriers.
not_cancelled %>% group_by(dest) %>%
mutate(num_carriers = length(unique(carrier))) %>%
filter(num_carriers > 1) %>%
group_by(carrier, add = T) %>%
summarise(avg_dep_delay = mean(dep_delay)) %>%
mutate(rank = dense_rank(avg_dep_delay)) %>%
group_by(carrier) %>%
summarise(avg_rank = mean(rank)) %>%
arrange(avg_rank)## # A tibble: 16 x 2
## carrier avg_rank
## <chr> <dbl>
## 1 AS 1.000000
## 2 HA 1.000000
## 3 DL 2.000000
## 4 US 2.000000
## 5 MQ 2.421053
## 6 AA 2.526316
## 7 UA 2.666667
## 8 9E 2.744681
## 9 VX 2.750000
## 10 WN 2.800000
## 11 B6 3.000000
## 12 EV 3.220000
## 13 FL 3.500000
## 14 OO 3.600000
## 15 F9 4.000000
## 16 YV 4.000000- For each plane, count the number of flights before the first delay of greater than 1 hour.
not_cancelled %>% group_by(tailnum) %>%
arrange(time_hour) %>%
mutate(num_before_big_delay = sum(cumall(dep_delay <60)))## # A tibble: 327,346 x 20
## # Groups: tailnum [4,037]
## year month day dep_time sched_dep_time dep_delay arr_time
## <int> <int> <int> <int> <int> <dbl> <int>
## 1 2013 1 1 517 515 2 830
## 2 2013 1 1 533 529 4 850
## 3 2013 1 1 542 540 2 923
## 4 2013 1 1 544 545 -1 1004
## 5 2013 1 1 554 558 -4 740
## 6 2013 1 1 559 559 0 702
## 7 2013 1 1 554 600 -6 812
## 8 2013 1 1 555 600 -5 913
## 9 2013 1 1 557 600 -3 709
## 10 2013 1 1 557 600 -3 838
## # ... with 327,336 more rows, and 13 more variables: sched_arr_time <int>,
## # arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
## # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
## # minute <dbl>, time_hour <dttm>, num_before_big_delay <int>7 EDA
7.3 Variation
- Explore the distribution of each of the x, y, and z variables in diamonds. What do you learn? Think about a diamond and how you might decide which dimension is the length, width, and depth.
data(diamonds)
gather(diamonds, k, v, x:z) %>%
ggplot(aes(v)) +
geom_histogram() +
facet_wrap(~k) +
xlim(0,10)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 11 rows containing non-finite values (stat_bin).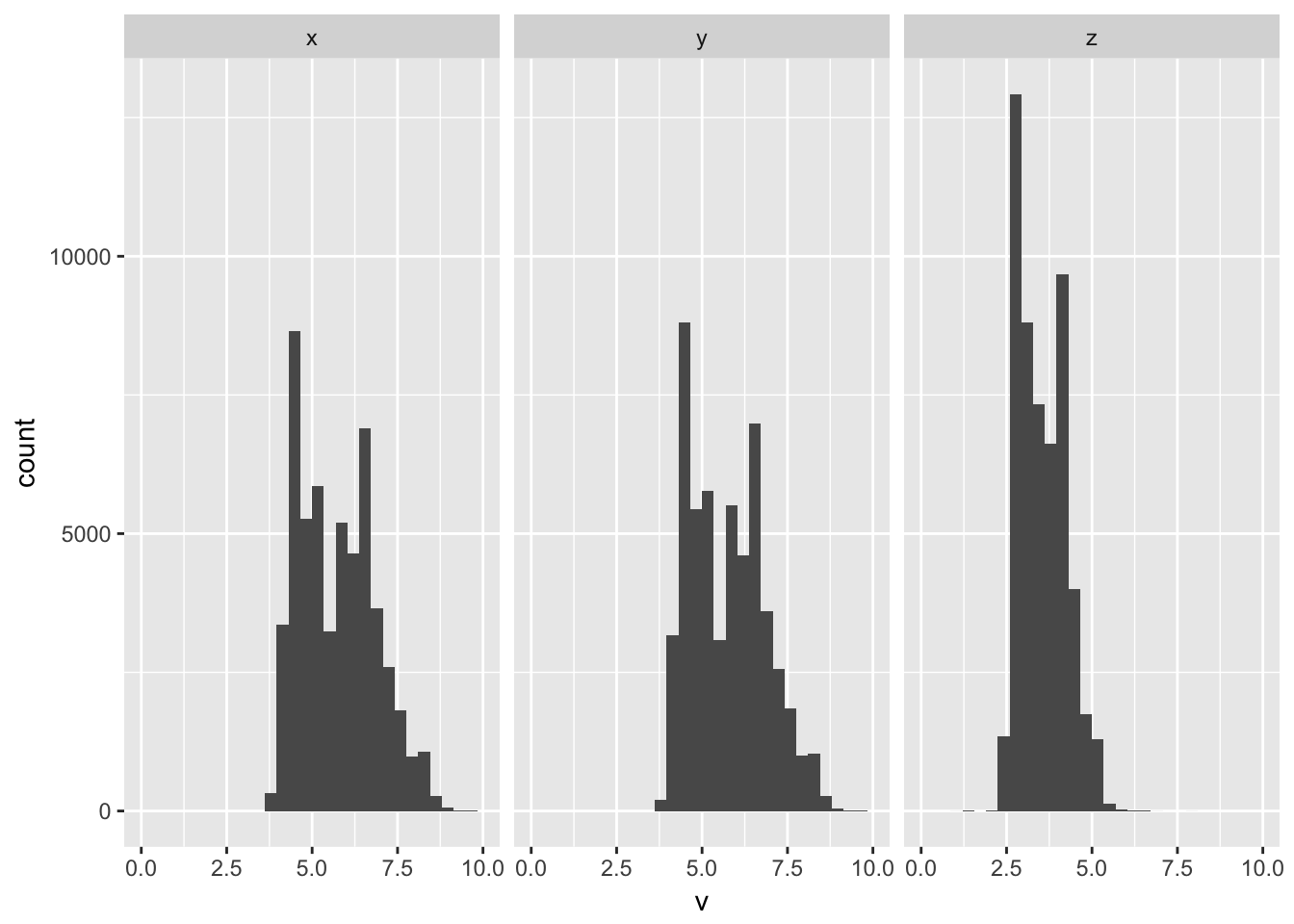 Z always seems the thinnest, and that makes sense if the diamond is set, it would likely be oriented to show with the thinnest dimension in the z-axis show the largest sides a presented in profile in the x and y dimensions.
Z always seems the thinnest, and that makes sense if the diamond is set, it would likely be oriented to show with the thinnest dimension in the z-axis show the largest sides a presented in profile in the x and y dimensions.
- Explore the distribution of price. Do you discover anything unusual or surprising? (Hint: Carefully think about the binwidth and make sure you try a wide range of values.)
ggplot(diamonds, aes(price)) +
geom_histogram(bins = 1000) +
scale_x_continuous(breaks = seq(0,15000, 1000))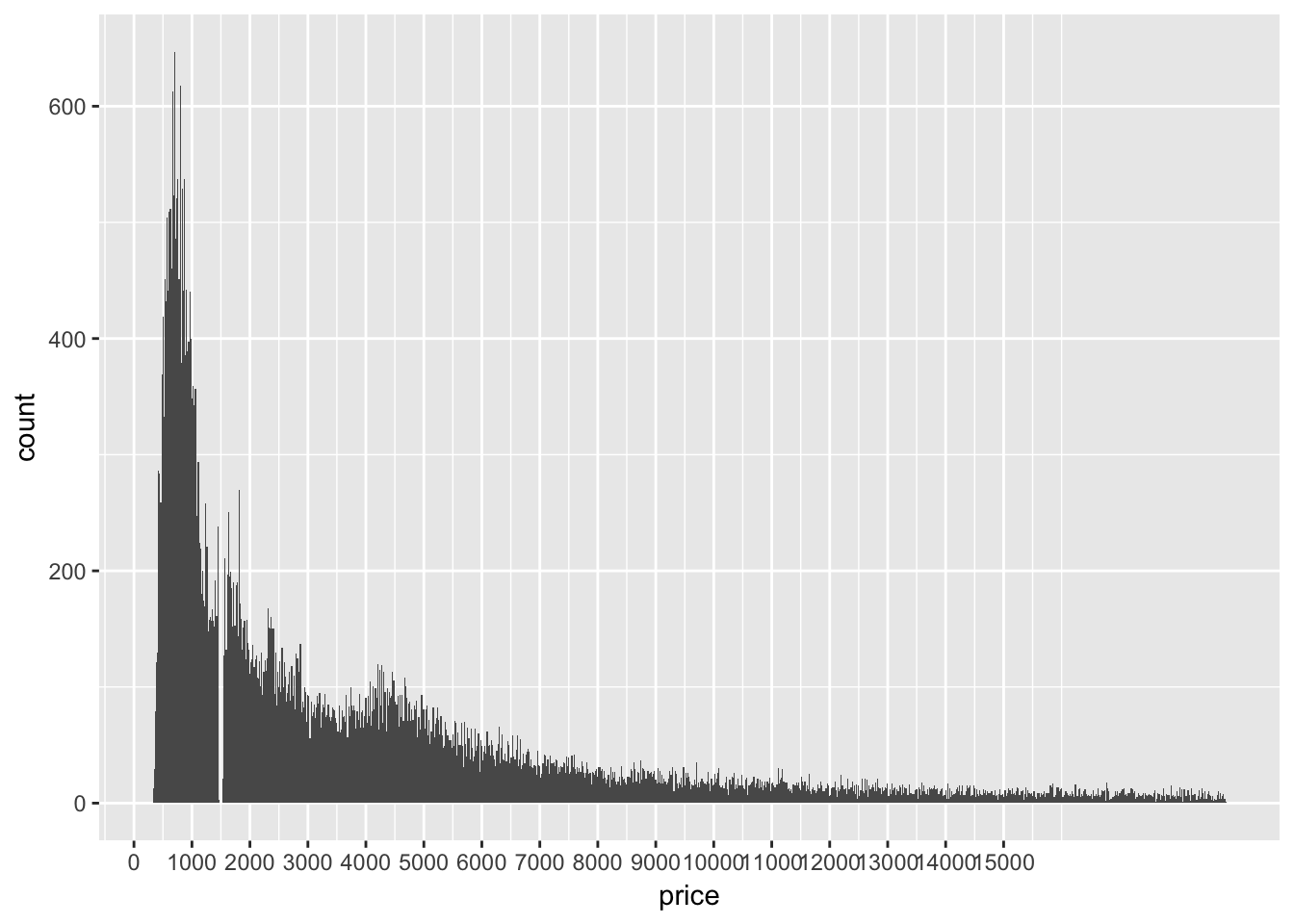 Why are there no diamonds being sold for $1500???
Why are there no diamonds being sold for $1500???
- How many diamonds are 0.99 carat? How many are 1 carat? What do you think is the cause of the difference?
diamonds %>% filter(carat %in% c(.99, 1)) %>%
with(., table(carat))## carat
## 0.99 1
## 23 1558When raw diamonds are being cut, it makes sense that jewlers would strive to keep diamonds as a whole carats. It is a better marketing piece to say 1,2 or 3 carat than .99, 1.99, 2.99, no one wants an almost.
- Compare and contrast coord_cartesian() vs xlim() or ylim() when zooming in on a histogram. What happens if you leave binwidth unset? What happens if you try and zoom so only half a bar shows?
ggplot(diamonds, aes(carat)) +
geom_histogram() +
coord_cartesian(xlim = c(0,3)) + #visual zoom, all data stays
ylim(c(0,10000)) # data outside range is converted to NA, dropped## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 1 rows containing missing values (geom_bar).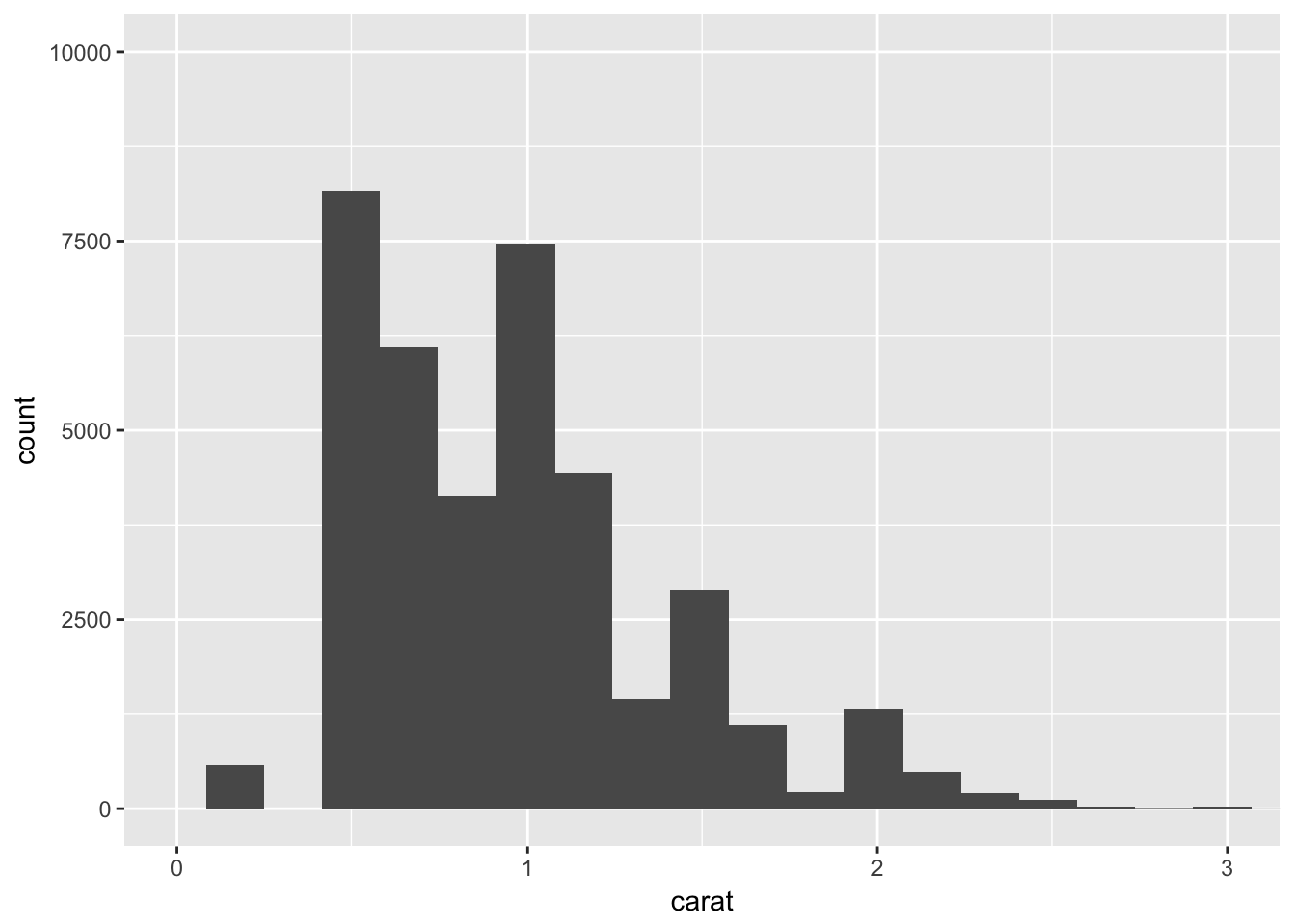
7.4 Missing values
What happens to missing values in a histogram? What happens to missing values in a bar chart? Why is there a difference?
ggplot(flights, aes(dep_delay)) +
geom_bar()## Warning: Removed 8255 rows containing non-finite values (stat_count).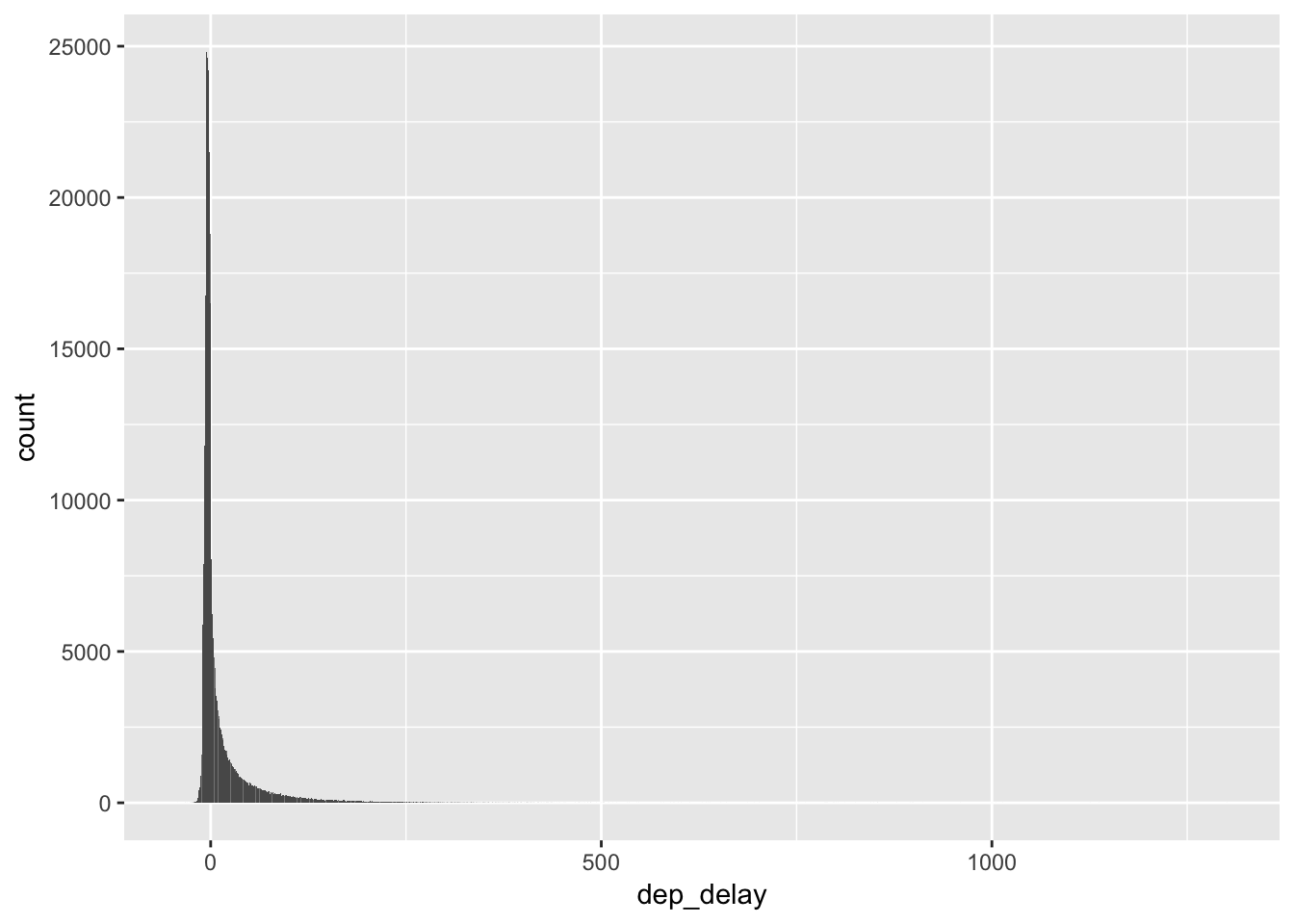
ggplot(flights, aes(dep_delay)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 8255 rows containing non-finite values (stat_bin).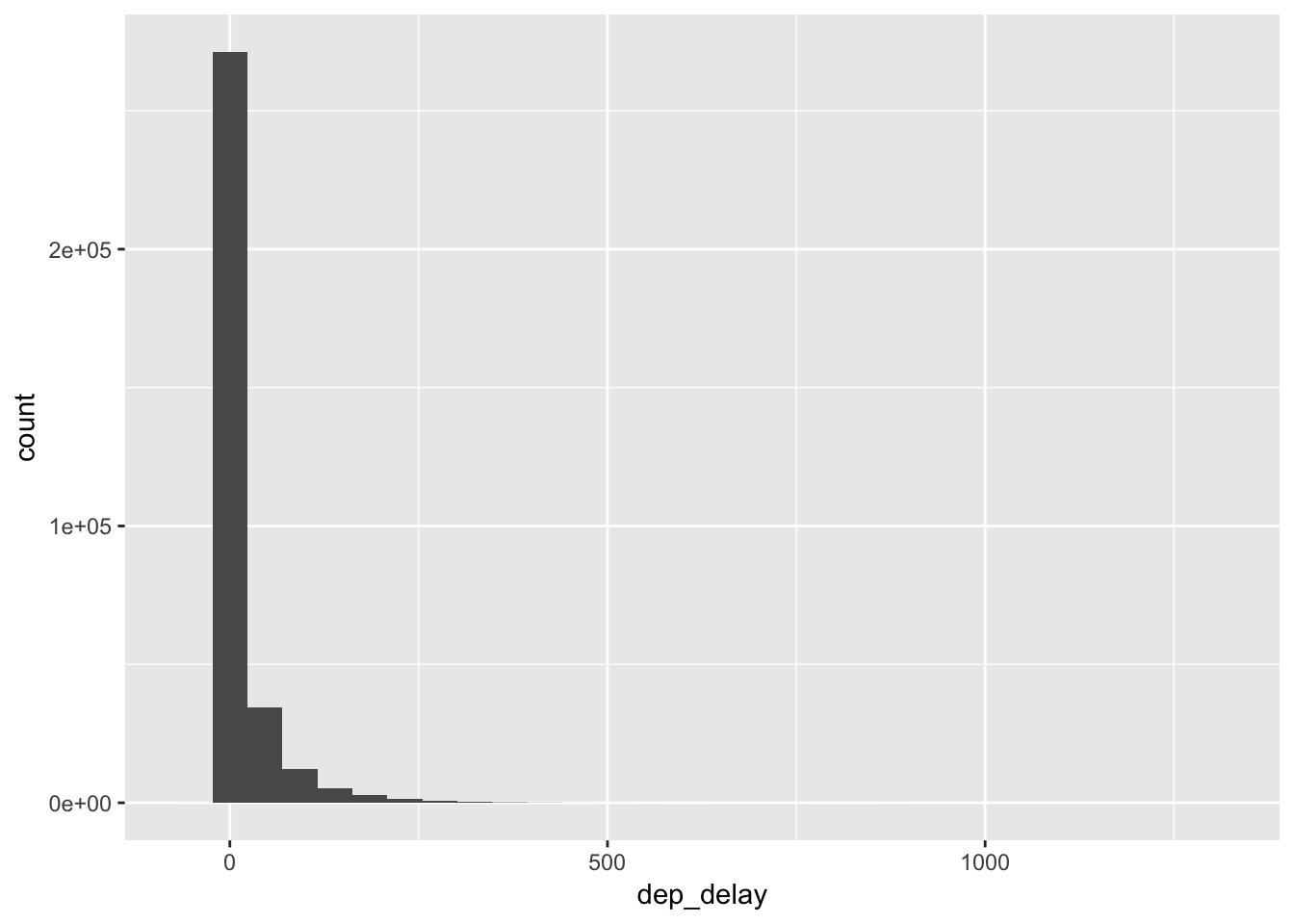
It seems like they handle the missing values the same, by giving a “Warning” and dropping them. Setting na.rm = TRUE would skip the warning and do the dropping silently.
- What does na.rm = TRUE do in mean() and sum()?
Saves you from getting the result of NA is NAs are present in your input vector. Remember NAs are “contagious” so any numeric summary would also be unknown because the NA values could be any number from -Inf to inf
7.5 Covariation
7.5.1 Continuous - Categorical
- Use what you’ve learned to improve the visualisation of the departure times of cancelled vs. non-cancelled flights.
flights %>% mutate(is_cancelled = is.na(dep_time)) %>%
ggplot(aes(sched_dep_time)) +
geom_density() +
facet_wrap(~is_cancelled)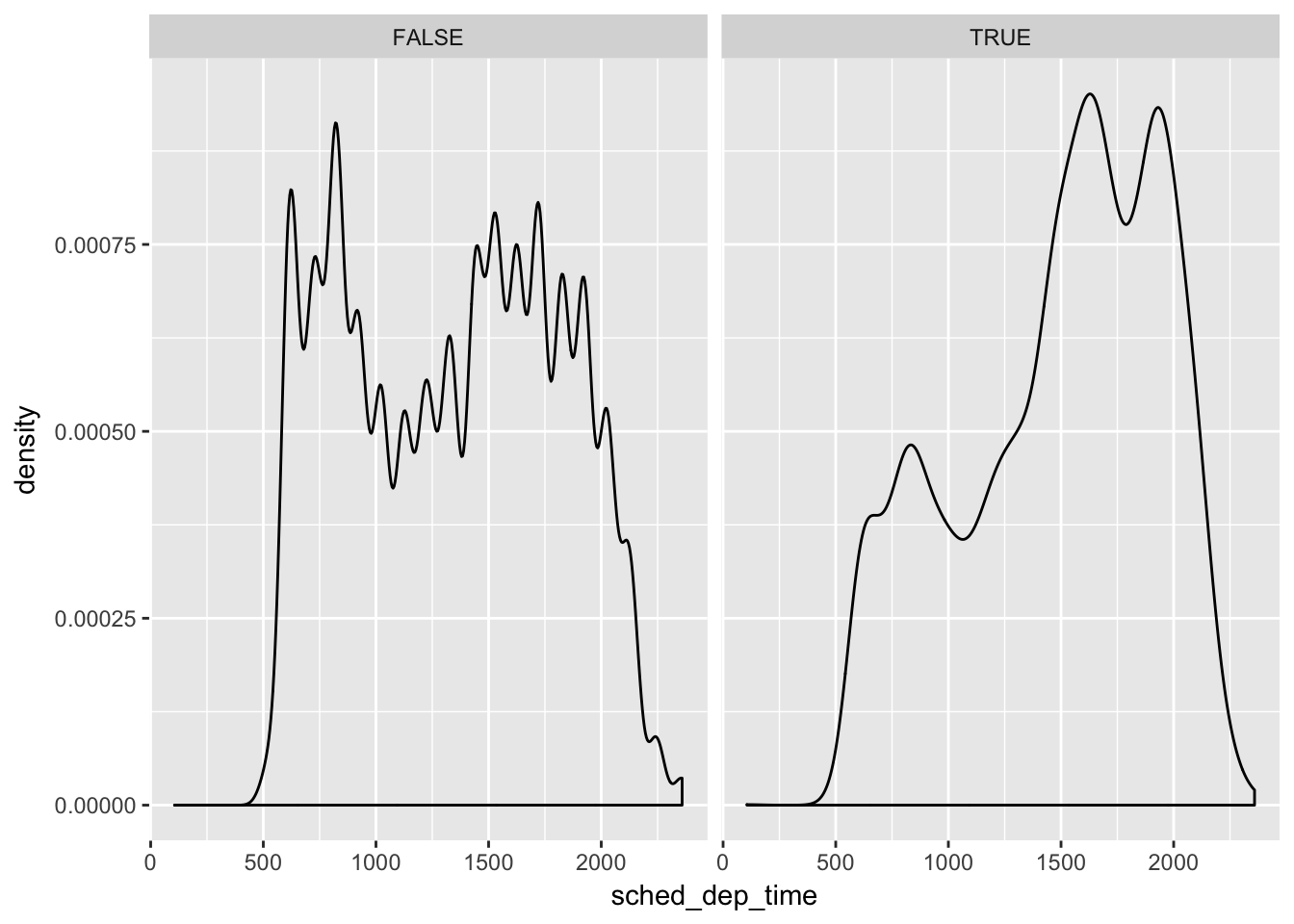
Most cancelled flights happend later in the day. There is a period between midnight and 5 am were there are very few flights departing NYC airports, I guess even pilots and air traffic personel like the sleep. Also considering that each plan (tailnum) makes multiple flights per day, if one earlier flight is delayed every subsequent flight is also delayed increasing the risk of cancellation as the day progresses.
- What variable in the diamonds dataset is most important for predicting the price of a diamond? How is that variable correlated with cut? Why does the combination of those two relationships lead to lower quality diamonds being more expensive?
library(GGally)##
## Attaching package: 'GGally'## The following object is masked from 'package:dplyr':
##
## nasasmall_diamonds <- sample_n(diamonds, 1000) # so it won't take forever
ggpairs(small_diamonds, columns = c(1:6)) # drop dimensions (table,x,y,z)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.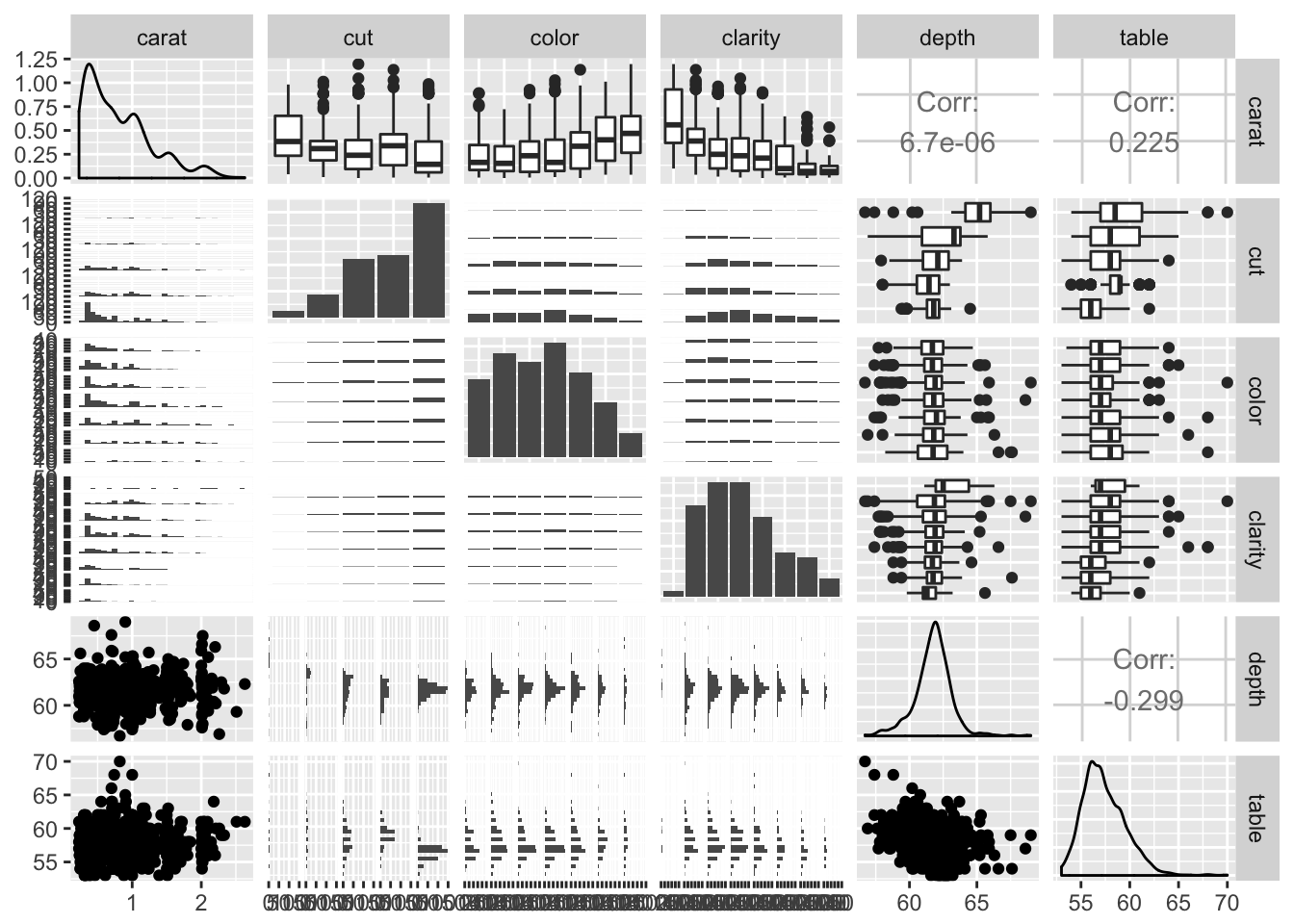
carat looks like it has a strong linear correlation with price. Let’s look closer and see how it relates to cut:
library(ggbeeswarm)
library(cowplot)##
## Attaching package: 'cowplot'## The following object is masked from 'package:ggplot2':
##
## ggsavecowplot::plot_grid(
ggplot(small_diamonds, aes(carat, price, color = cut)) +
geom_point(alpha = .5),
ggplot(small_diamonds, aes(cut, price)) +
geom_quasirandom(alpha = .1)
)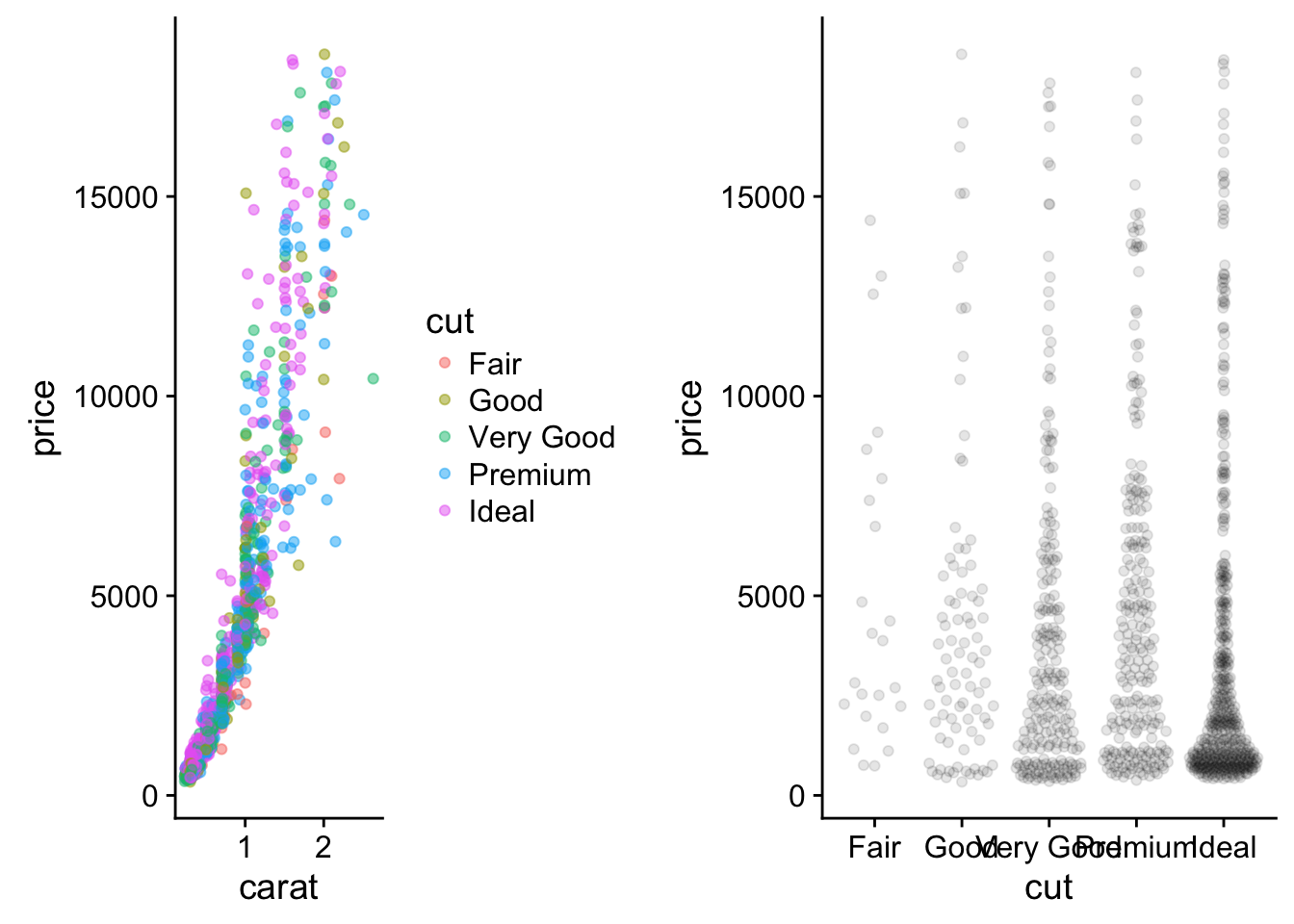
It looks like the biggest diamonds available are not “ideal” in their cut, but despite that people are still willing to pay a premium. However it looks like cut is does have a positive correlation with price. Overall there a lot more diamonds being classified as “ideal” and that makes sense because diamonds are an artificial market driven entirely by mining company supply restrictions and advertising. Lower quality diamonds make there way into industrial applications, for their strength properties and the better cuts are left for the premiums in the jewlery market.
- Install the ggstance package, and create a horizontal boxplot. How does this compare to using coord_flip()?
# install.packages("ggstance")
library(ggstance)##
## Attaching package: 'ggstance'## The following objects are masked from 'package:ggplot2':
##
## geom_errorbarh, GeomErrorbarhggplot(small_diamonds, aes(x = price, y = cut)) +
stat_boxploth()
# you just have to change the axis assignments
ggplot(small_diamonds, aes(x = cut, y = price)) +
geom_boxplot() +
coord_flip()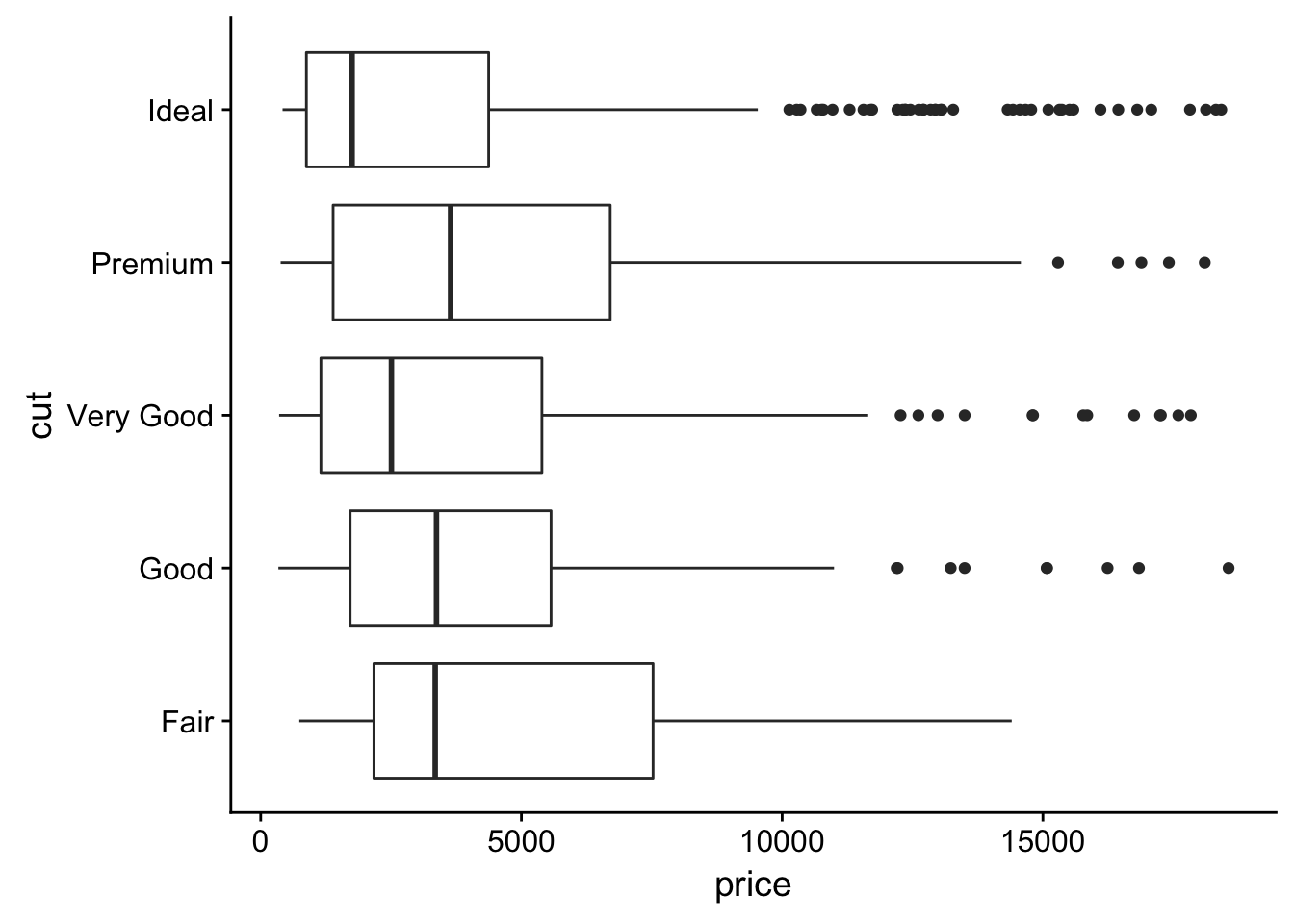
- One problem with boxplots is that they were developed in an era of much smaller datasets and tend to display a prohibitively large number of “outlying values”. One approach to remedy this problem is the letter value plot. Install the lvplot package, and try using geom_lv() to display the distribution of price vs cut. What do you learn? How do you interpret the plots?
# need github version, not CRAN
# devtools::install_github("hadley/lvplot")
library(lvplot)
ggplot(diamonds, aes(x = cut, y = price)) +
geom_lv() # ewwwwwy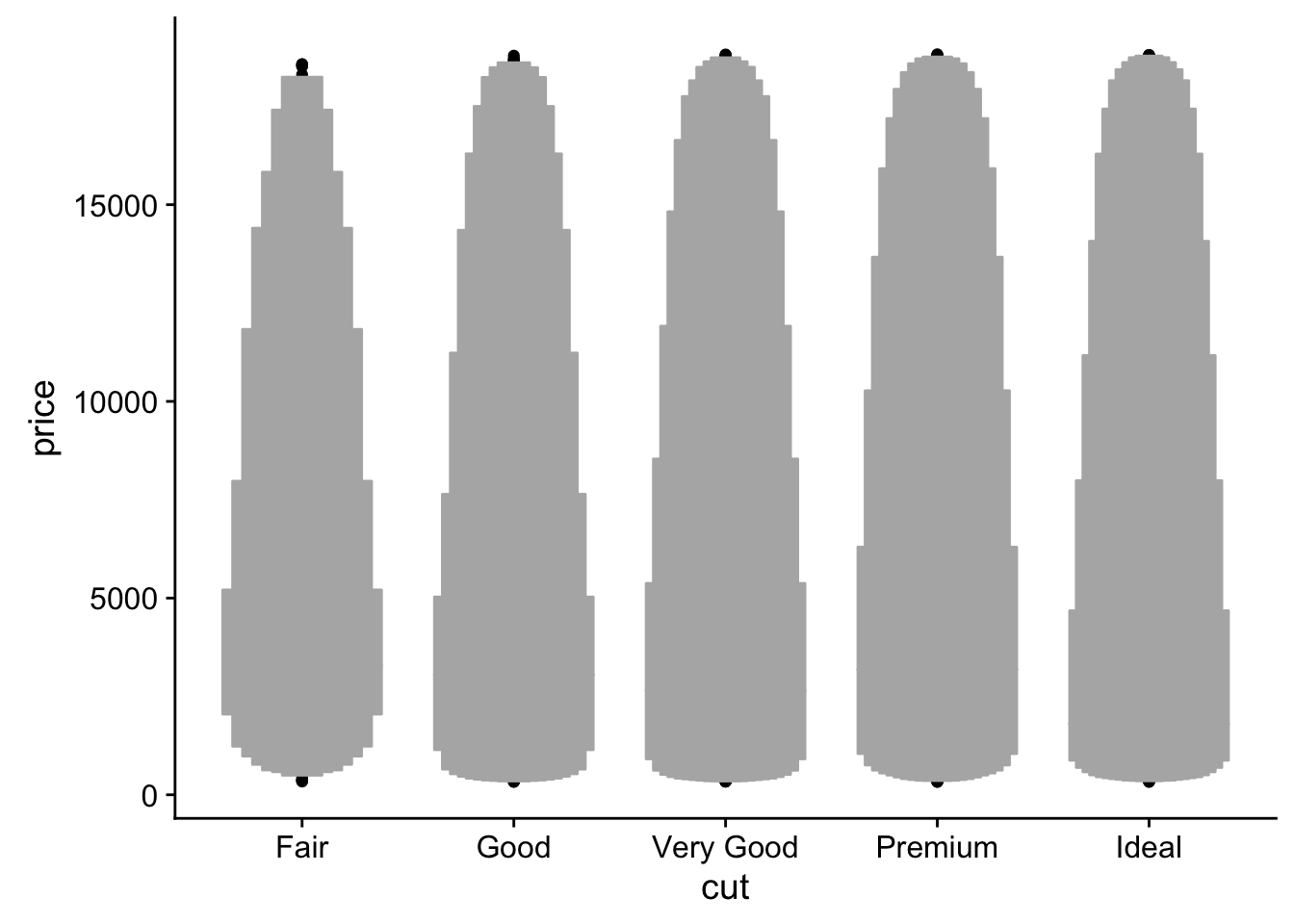
The idea behind letter value plots was to reduce the over calling of outliers in larger (n > 1000) data sets. and reduce the number of points marked as outliers.
- Compare and contrast geom_violin() with a facetted geom_histogram(), or a coloured geom_freqpoly(). What are the pros and cons of each method?
ggplot(small_diamonds, aes(cut, carat)) +
geom_violin()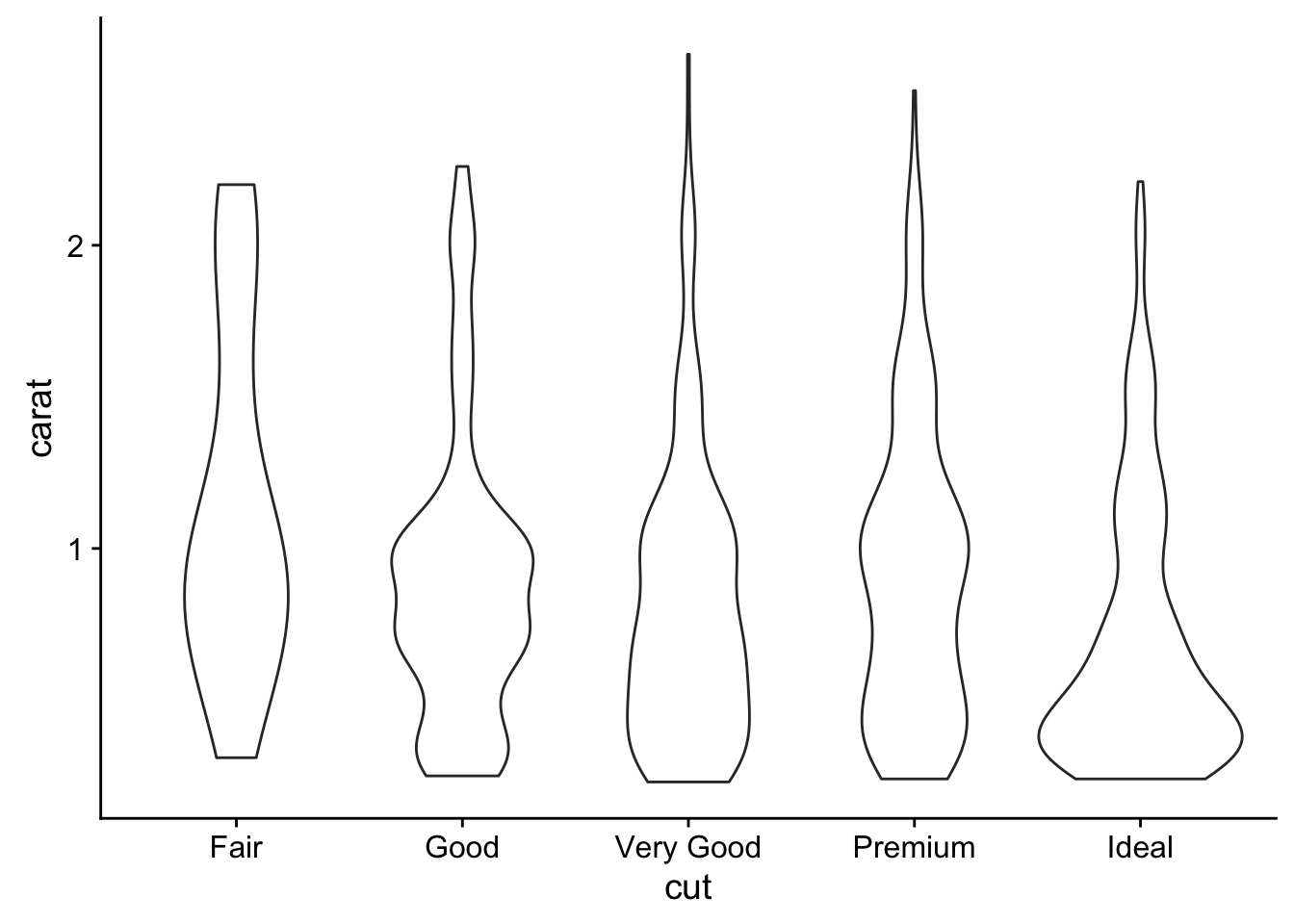
# shows the distribution in a mirrored density curve
ggplot(small_diamonds, aes(carat)) +
geom_histogram() +
facet_wrap(~cut, scales = "free")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.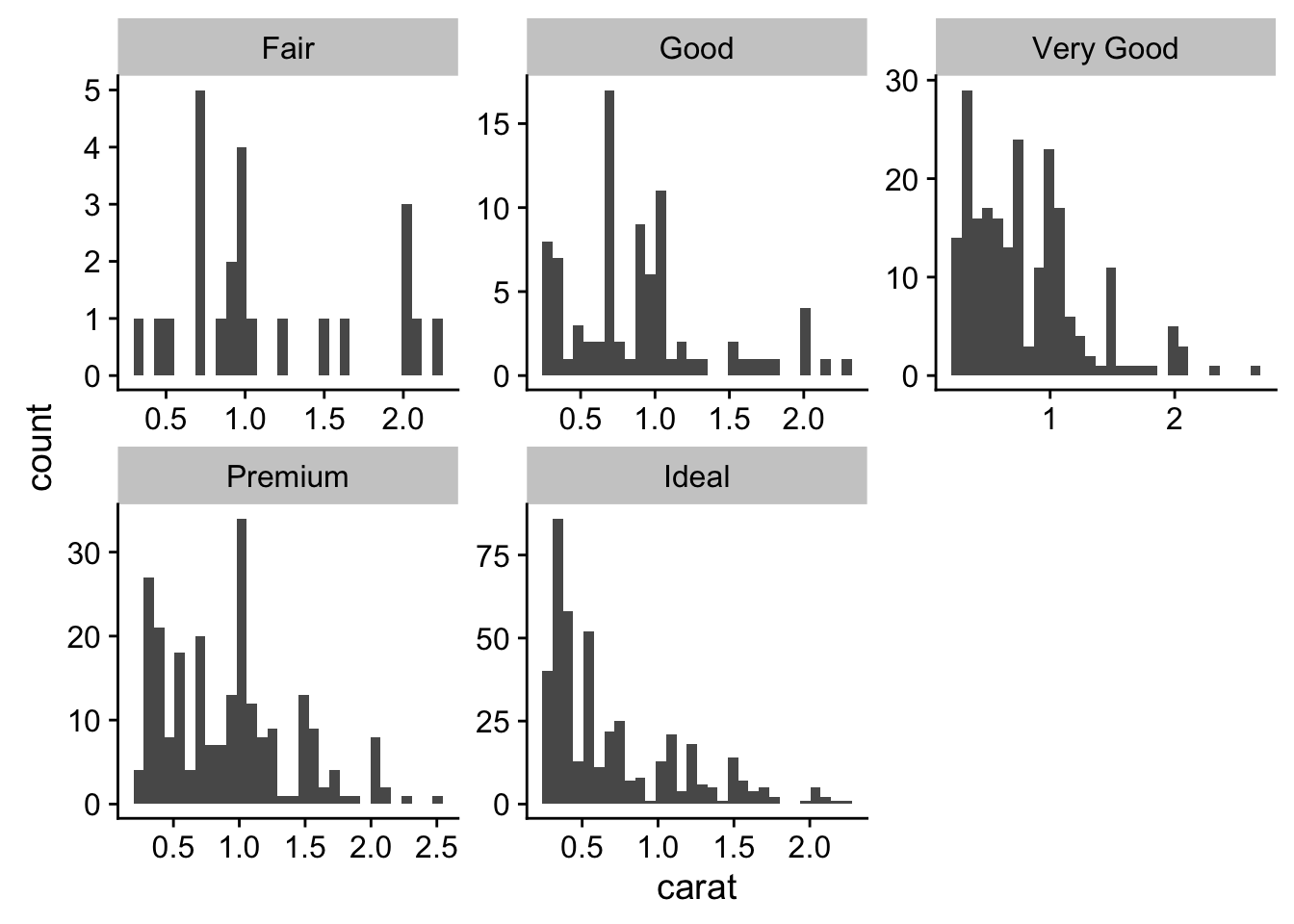
# hard to make distribution comparisons since histogram uses count to determin bar height
# geom_density() is what I prefer
ggplot(small_diamonds, aes(carat)) +
geom_density() +
facet_wrap(~cut)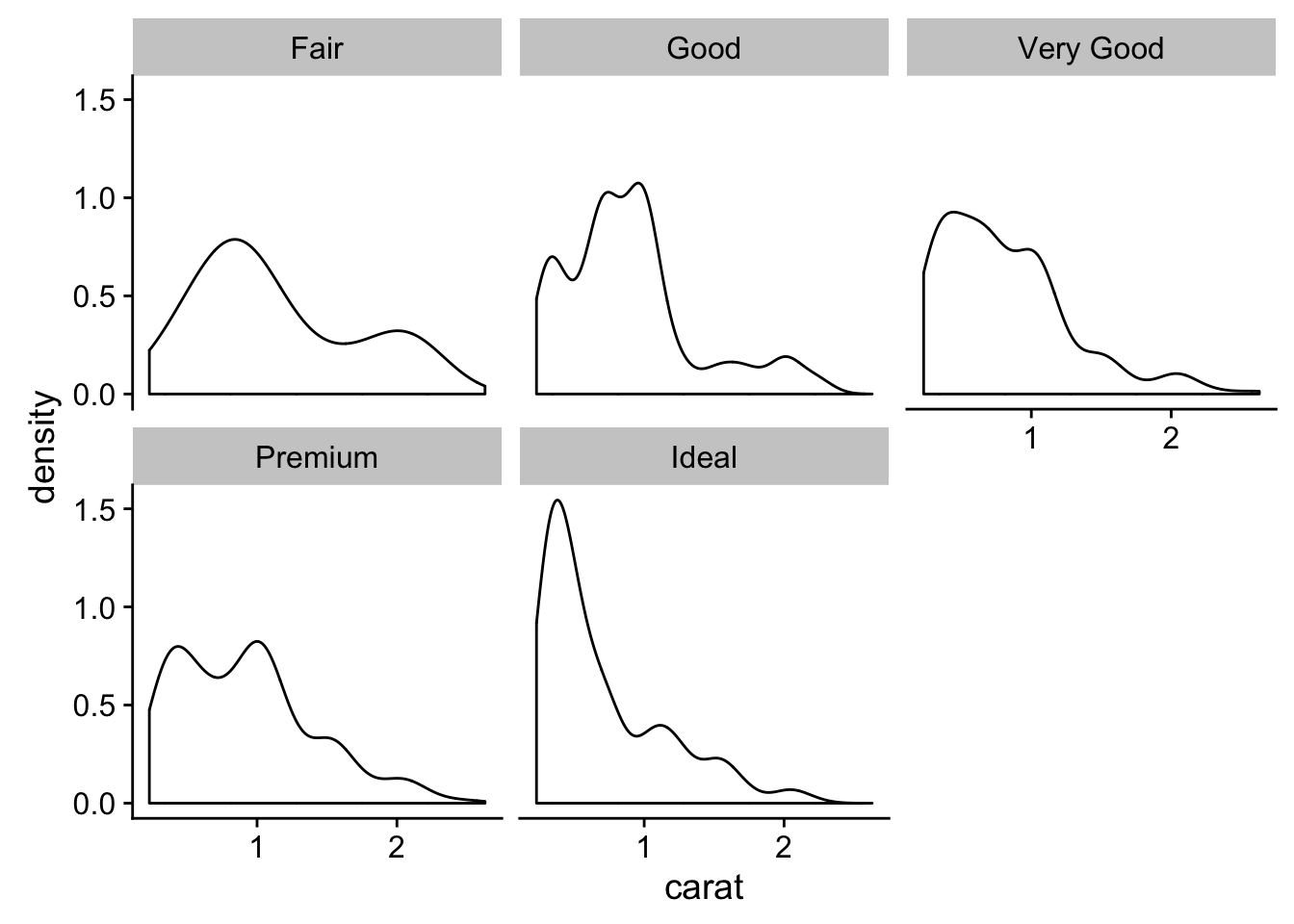
- If you have a small dataset, it’s sometimes useful to use geom_jitter() to see the relationship between a continuous and categorical variable. The ggbeeswarm package provides a number of methods similar to geom_jitter(). List them and briefly describe what each one does.
library(ggbeeswarm)
ggplot(small_diamonds, aes(cut, carat)) +
geom_quasirandom()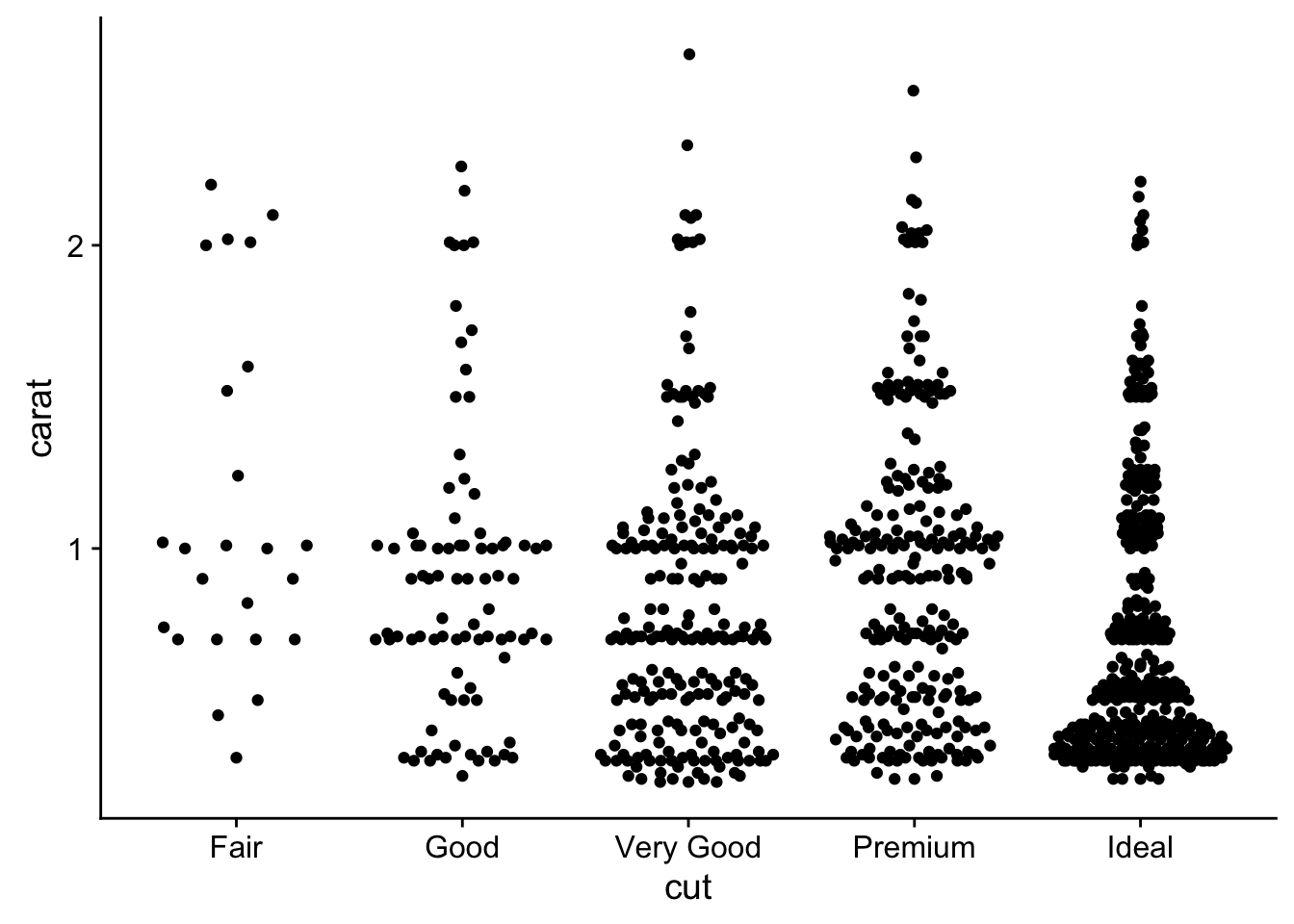
This is similar to geom_violin, in that it attempts show the density via width and similar to jitter in that overalpping points are dodged. The alternate function is geom_beeswarm() which just uses a slightly different positioning algorithim to re-located overlapping points.
7.5.2 Two categorical variables
- How could you rescale the count dataset above to more clearly show the distribution of cut within colour, or colour within cut?
counts <- diamonds %>%
count(color, cut)
library(viridis)## Loading required package: viridisLiteggplot(counts, aes(color, y = cut, fill = n)) +
geom_tile() +
scale_fill_viridis() # use a better color palette is one option for better viz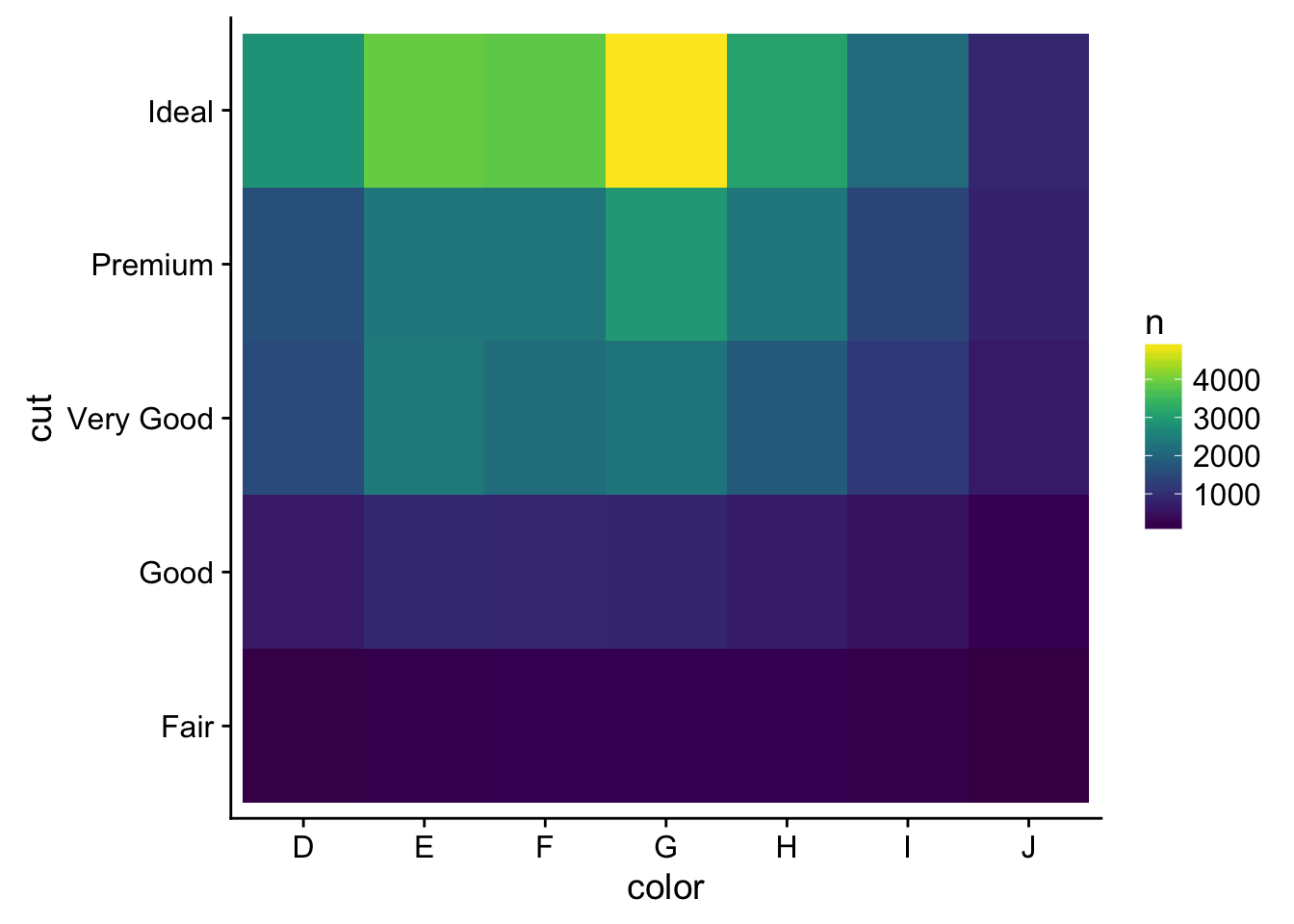
# or add a new proportional summary value
counts2 <- counts %>%
group_by(color) %>%
mutate(total = sum(n),
prop = n / total)
ggplot(counts2, aes(color, cut, fill = prop)) +
geom_tile() +
scale_fill_viridis()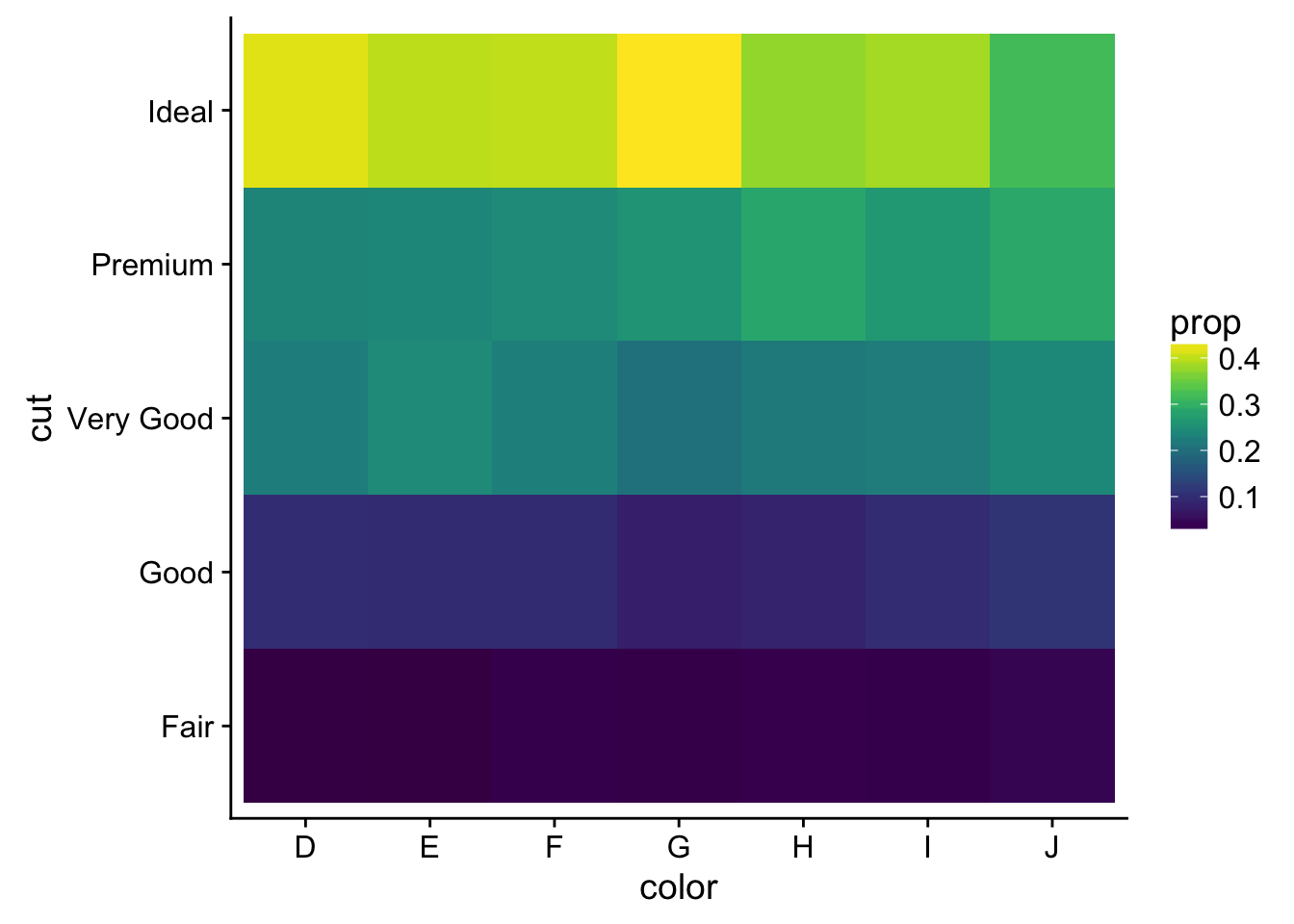
- Use geom_tile() together with dplyr to explore how average flight delays vary by destination and month of year. What makes the plot difficult to read? How could you improve it?
not_cancelled %>% group_by(dest, month) %>%
summarise(avg_delay = mean(dep_delay)) %>%
ggplot(aes(month, dest, fill = avg_delay)) +
geom_tile()
# there are too many desinations (and blue pallete is bad)
# lets filter to only very common destimations
top_dests <- not_cancelled %>% group_by(dest) %>%
count(sort = T) %>% .[1:10,] # top10
not_cancelled %>% filter(dest %in% top_dests$dest) %>%
group_by(dest, month) %>%
summarise(avg_delay = mean(dep_delay)) %>%
ggplot(aes(month, dest, fill = avg_delay)) +
geom_tile() +
scale_fill_viridis() # ftw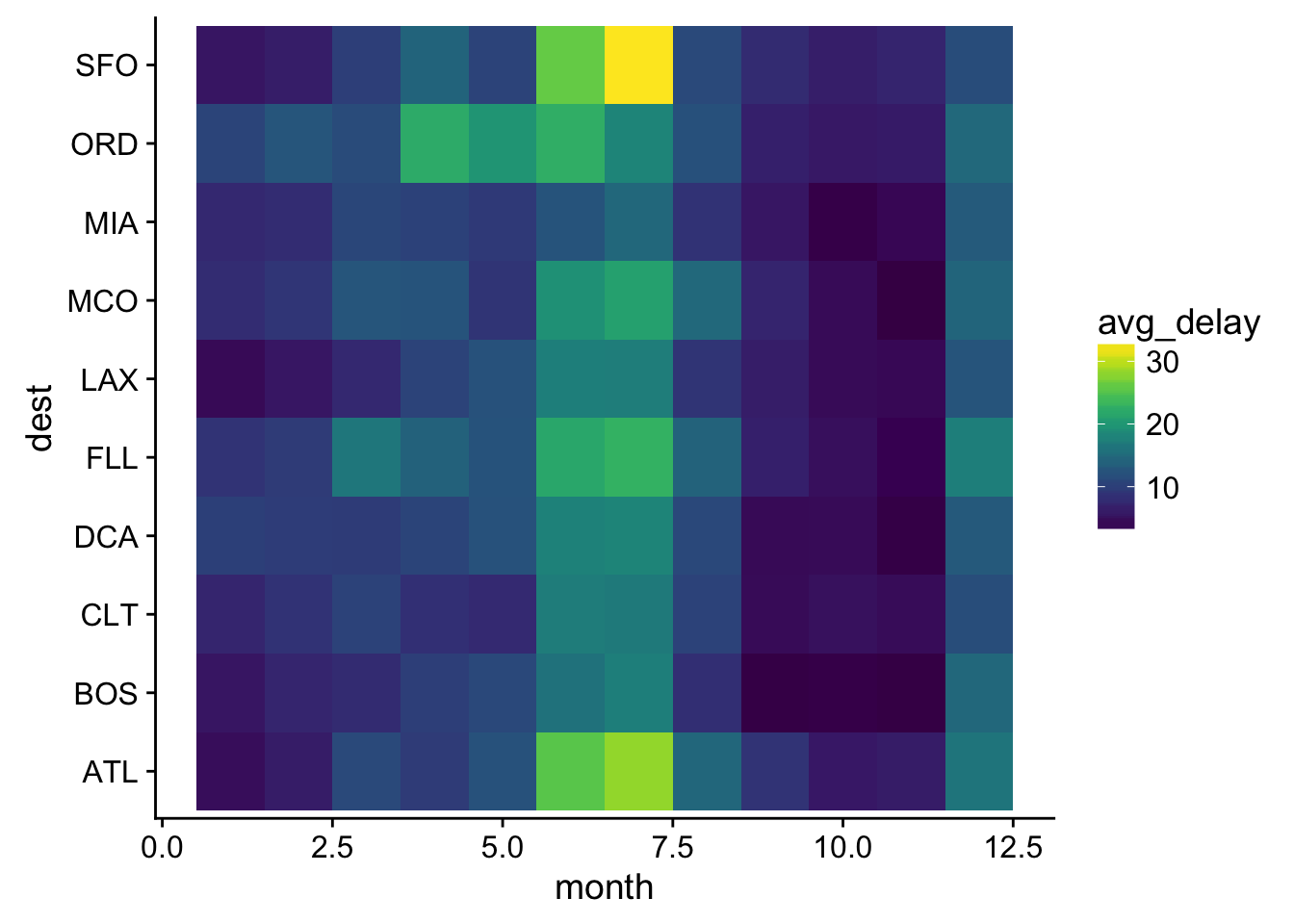
- Why is it slightly better to use aes(x = color, y = cut) rather than aes(x = cut, y = color) in the example above?
ggplot(counts2, aes(cut, color, fill = prop)) +
geom_tile() +
scale_fill_viridis() # hmmm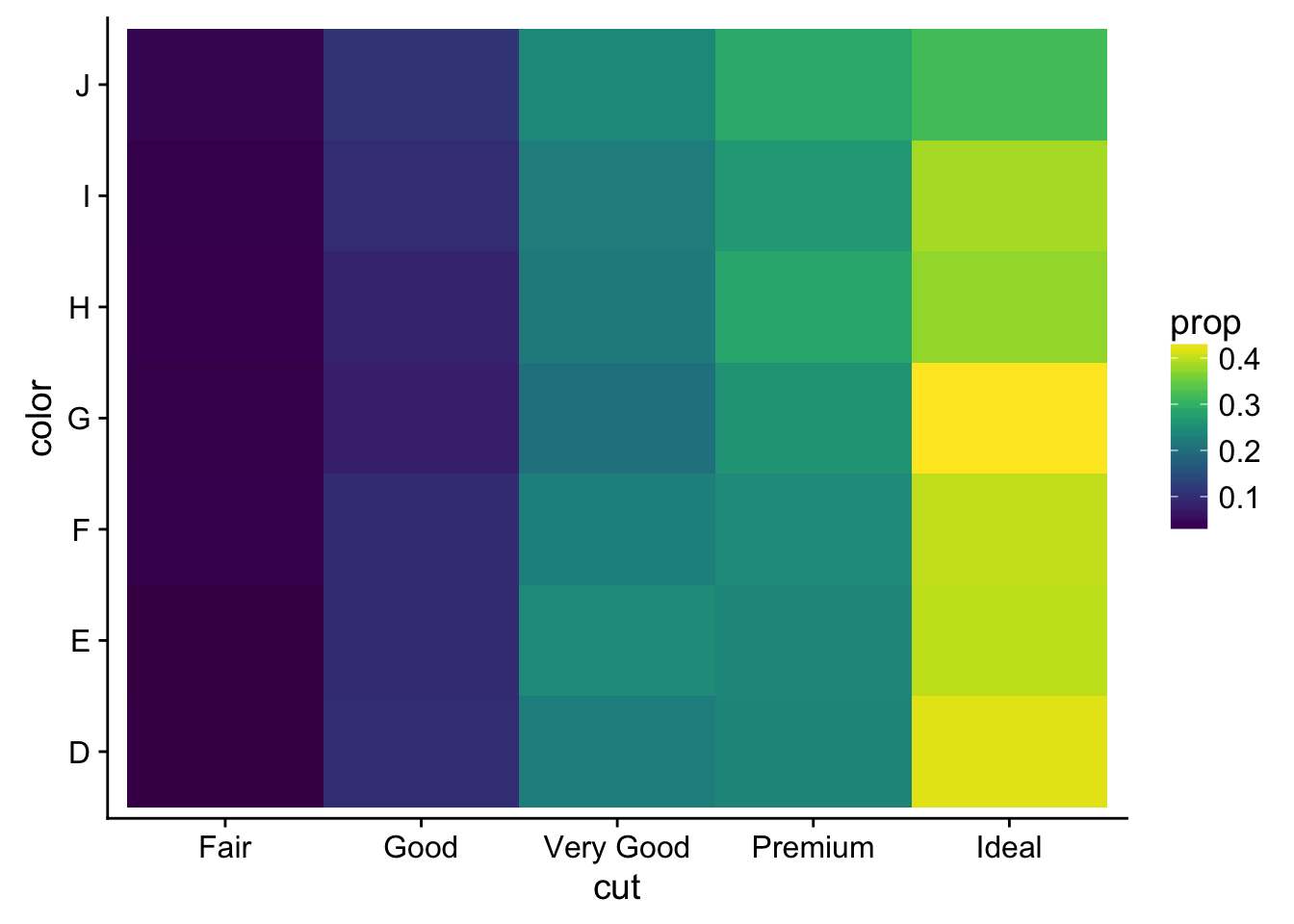
Crystal Passmore: There are more levels in diamonds$color so it makes more sense to put the factor with more levels on the x-axis.
7.5.3 Two continuous variables
- Instead of summarising the conditional distribution with a boxplot, you could use a
geom_freqpoly(). What do you need to consider when using the argumentsbinwidth =andbins =? How does that impact a visualisation of the 2d distribution of carat and price?
# bins() vs bin_width() is a matter of preference
ggplot(diamonds, aes(price, colour = cut)) +
geom_freqpoly(bins = 5000) # dont want to over-fit 
ggplot(diamonds, aes(price, colour = cut)) +
geom_freqpoly(bins = 5) # or lose trends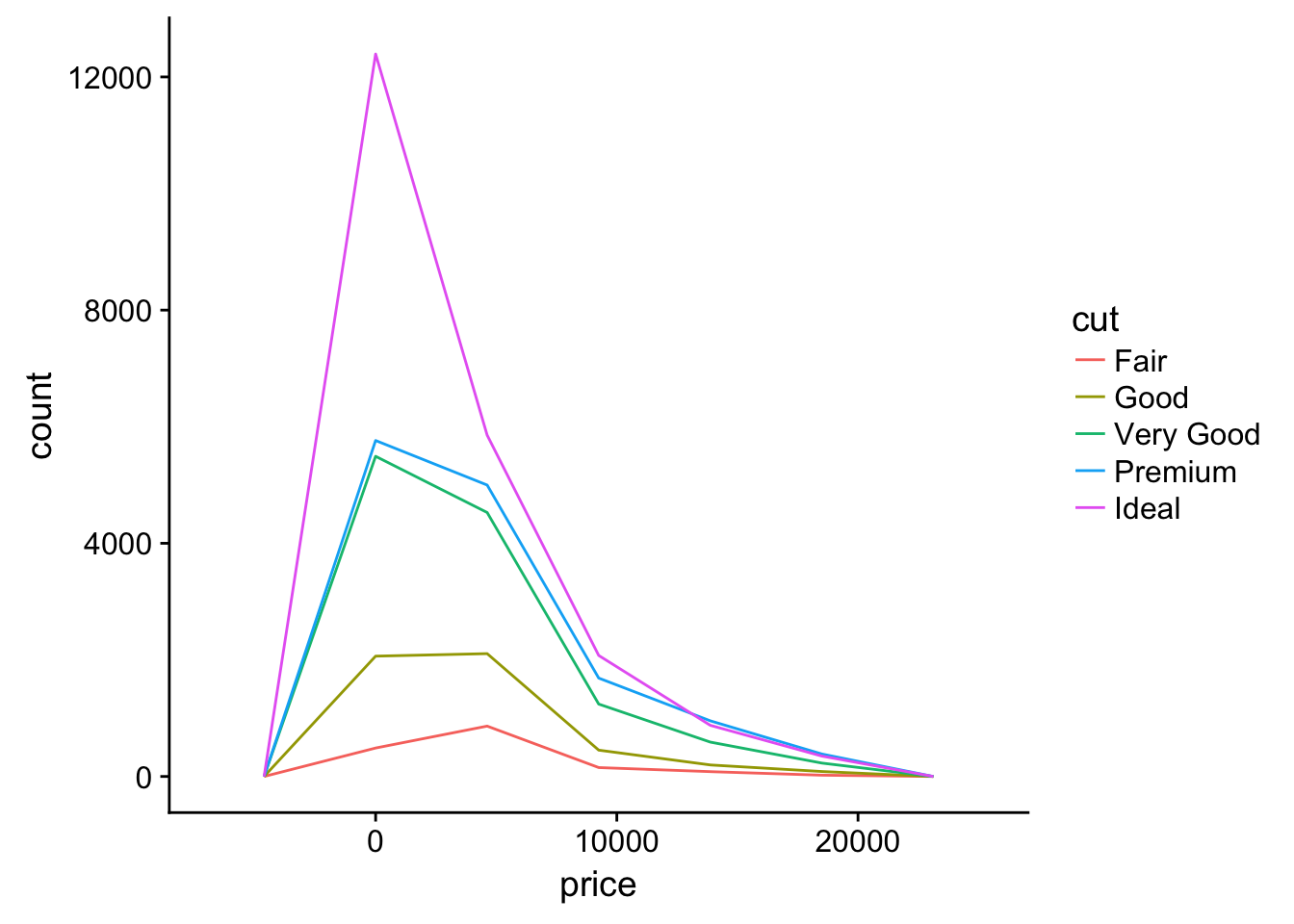
- Visualise the distribution of carat, partitioned by price.
diamonds %>% mutate(facets = cut_number(price, 3)) %>%
ggplot(aes(carat)) +
geom_freqpoly(aes(color = facets)) +
ggsci::scale_color_d3(labels = c("S", "M", "L")) +
xlim(0,2.5)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 126 rows containing non-finite values (stat_bin).## Warning: Removed 6 rows containing missing values (geom_path).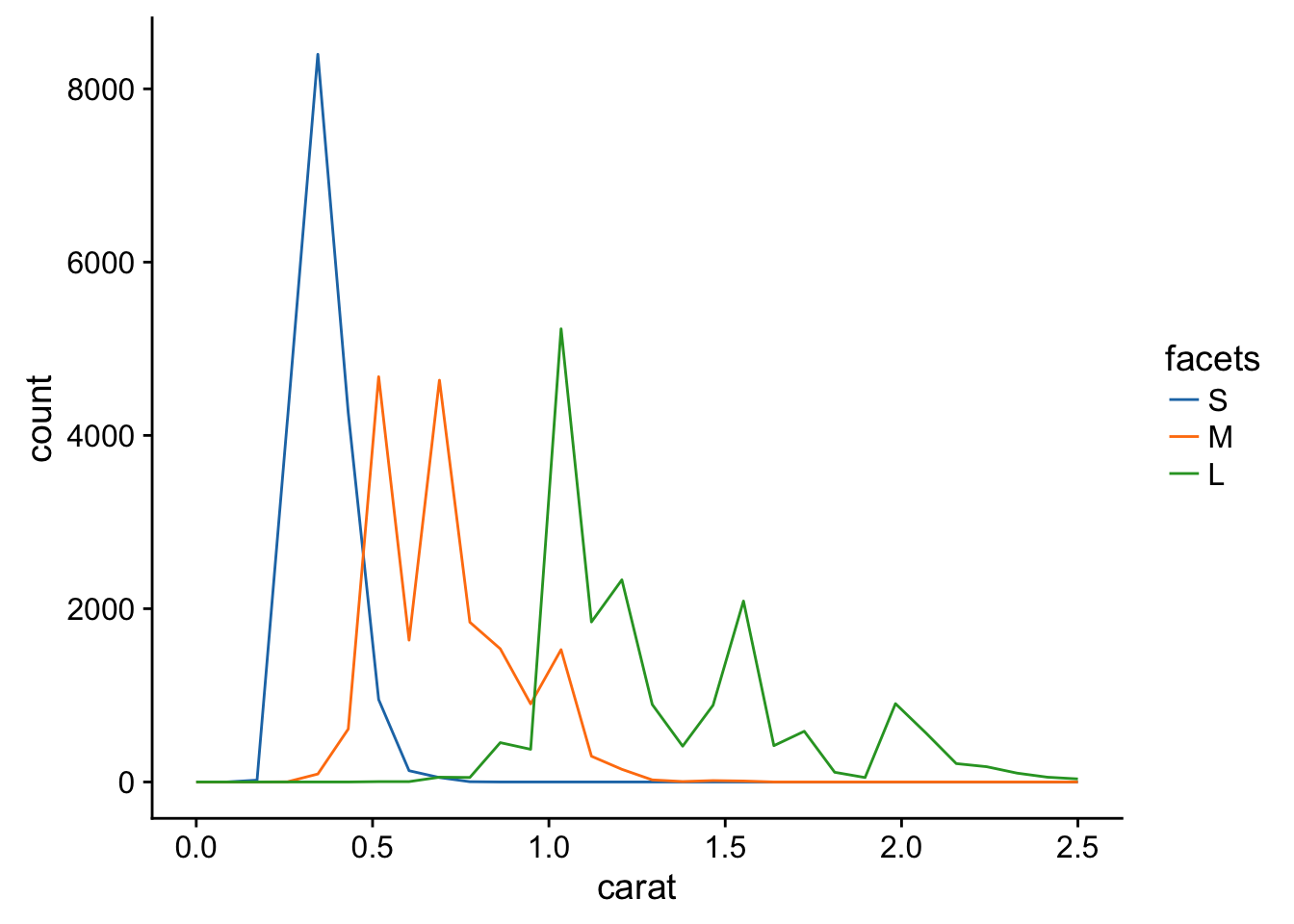
- How does the price distribution of very large diamonds compare to small diamonds. Is it as you expect, or does it surprise you?
# check range
range(diamonds$carat)## [1] 0.20 5.01quantile(diamonds$carat)## 0% 25% 50% 75% 100%
## 0.20 0.40 0.70 1.04 5.01# use probs arg to cut out small and large diamonds
c1 <- quantile(diamonds$carat, probs = .1) # bottom 10%
c2 <- quantile(diamonds$carat, .9) # top 10%
# now for real
diamonds %>% mutate(size_cut = Hmisc::cut2( diamonds$carat, cuts = c(c1, c2) ) ) %>%
ggplot(aes(price)) +
geom_density(aes(color = size_cut)) +
ggsci::scale_color_d3(labels = c("bottom10", "middle80", "top10") )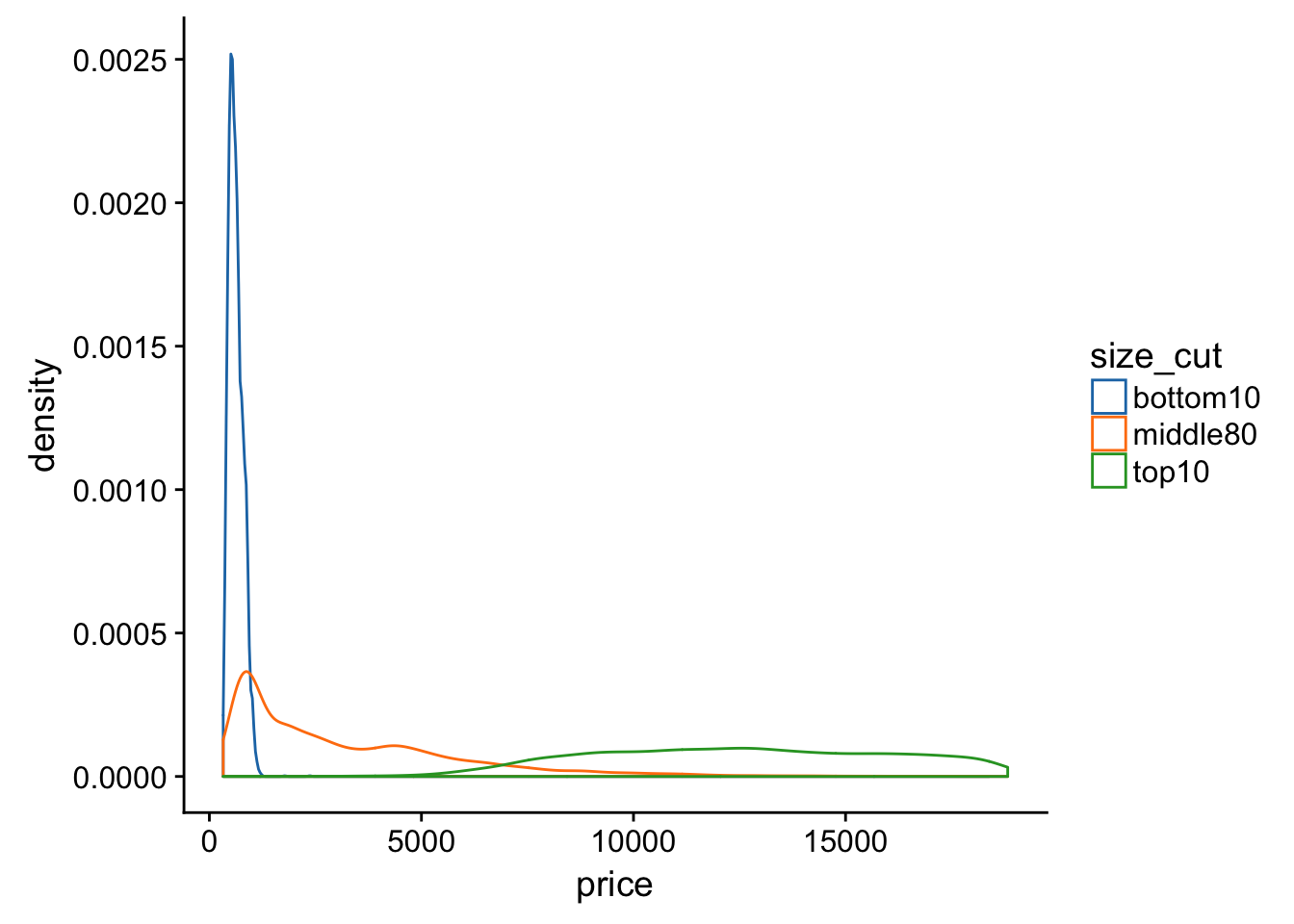
- Combine two of the techniques you’ve learned to visualise the combined distribution of cut, carat, and price.
diamonds %>% mutate(facets = cut_number(price, 3),
size_cut = Hmisc::cut2( diamonds$carat, cuts = quantile(diamonds$carat)[2:4] )) %>%
ggplot(aes(carat, color = size_cut)) +
geom_freqpoly() +
facet_grid(~facets) +
ggsci::scale_color_d3(labels = paste0("Q", 1:4)) +
xlim(0,2.5) # ???## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 126 rows containing non-finite values (stat_bin).## Warning: Removed 8 rows containing missing values (geom_path).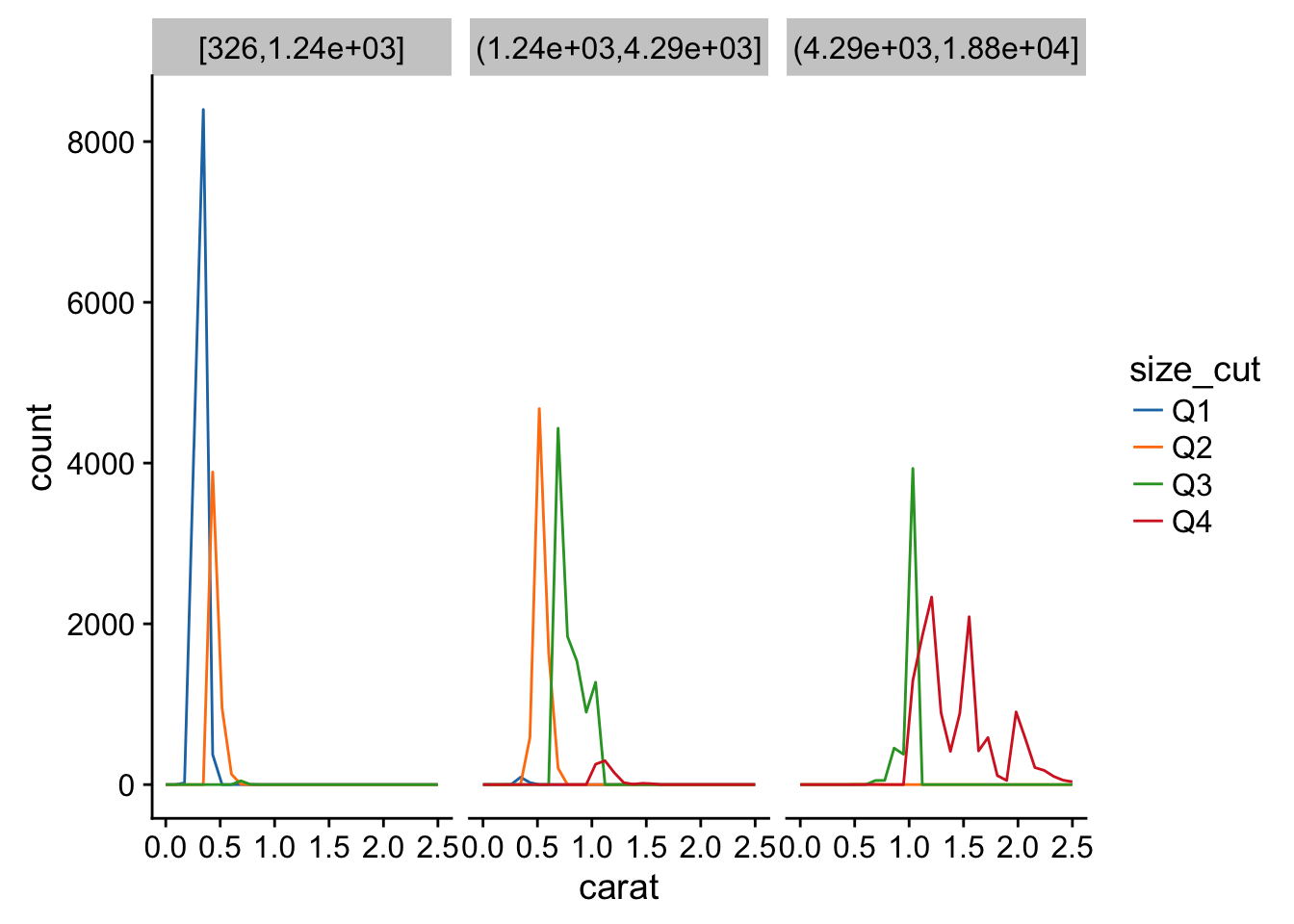
10 Tibbles
10.5
- How can you tell if an object is a tibble? (Hint: try printing mtcars, which is a regular data frame).
class(mtcars)## [1] "data.frame"mtcars## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
## Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
## Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
## Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
## Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
## Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
## Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
## Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
## Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
## Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
## Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
## Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
## AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
## Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
## Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
## Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2mtcars %>% as.tibble()## # A tibble: 32 x 11
## mpg cyl disp hp drat wt qsec vs am gear carb
## * <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## 5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## 7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## 8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## 10 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## # ... with 22 more rowsOr you can print it and if its a tibble it will only print the first 10 rows and look like this:
mtcars %<>% as.tibble
mtcars## # A tibble: 32 x 11
## mpg cyl disp hp drat wt qsec vs am gear carb
## * <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## 5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## 7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## 8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## 10 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## # ... with 22 more rows- Compare and contrast the following operations on a data.frame and equivalent tibble. What is different? Why might the default data frame behaviours cause you frustration?
df <- data.frame(abc = 1, xyz = "a")
tib <- tibble(abc = 1, xyz = "a")
# using a list for a container
li <- list(df, tib)
# using map to iterate (ie apply a fxn to each element)
# df$x
map(li, ~ .$x)## Warning: Unknown or uninitialised column: 'x'.## [[1]]
## [1] a
## Levels: a
##
## [[2]]
## NULL# tibbles don't have lazy matching, base R does. You must be specific about colnames with tibbles
map(li, ~.$xyz)## [[1]]
## [1] a
## Levels: a
##
## [[2]]
## [1] "a"# also tibbles don't automatically coherce characters to factors while base R does. You can get around that behavior by setting:
options(stringsAsFactors = FALSE)
# df[, "xyz"]
df[, "xyz"]## [1] a
## Levels: atib[, "xyz"]## # A tibble: 1 x 1
## xyz
## <chr>
## 1 amap(li, ~.[,"xyz"])## [[1]]
## [1] a
## Levels: a
##
## [[2]]
## # A tibble: 1 x 1
## xyz
## <chr>
## 1 a# A tibble will return the whole row, while a data frame with return only the value in that column "xyz"
# df[, c("abc", "xyz")]
map(li, ~.[, c("abc", "xyz")])## [[1]]
## abc xyz
## 1 1 a
##
## [[2]]
## # A tibble: 1 x 2
## abc xyz
## <dbl> <chr>
## 1 1 a# since the data frame is only two columns wide these return the same thing. A data frame only returns columns that are explicitly referenced and a tibble returns the entire observation (row)- If you have the name of a variable stored in an object, e.g. var <- “mpg”, how can you extract the reference variable from a tibble?
var <- "mpg"
mt_tib <- as.tibble(mtcars)
mt_tib[var] # mt_tib$var fails## # A tibble: 32 x 1
## mpg
## <dbl>
## 1 21.0
## 2 21.0
## 3 22.8
## 4 21.4
## 5 18.7
## 6 18.1
## 7 14.3
## 8 24.4
## 9 22.8
## 10 19.2
## # ... with 22 more rows- Practice referring to non-syntactic names in the following data frame by:
annoying <- tibble(
`1` = 1:10,
`2` = `1` * 2 + rnorm(length(`1`))
)4a. Extracting the variable called 1.
annoying$`1` # use backticks## [1] 1 2 3 4 5 6 7 8 9 10annoying[1] # a happy positional coincidence## # A tibble: 10 x 1
## `1`
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
## 8 8
## 9 9
## 10 104b. Plotting a scatterplot of 1 vs 2.
annoying %>%
ggplot(aes(`1`, `2`)) +
geom_point()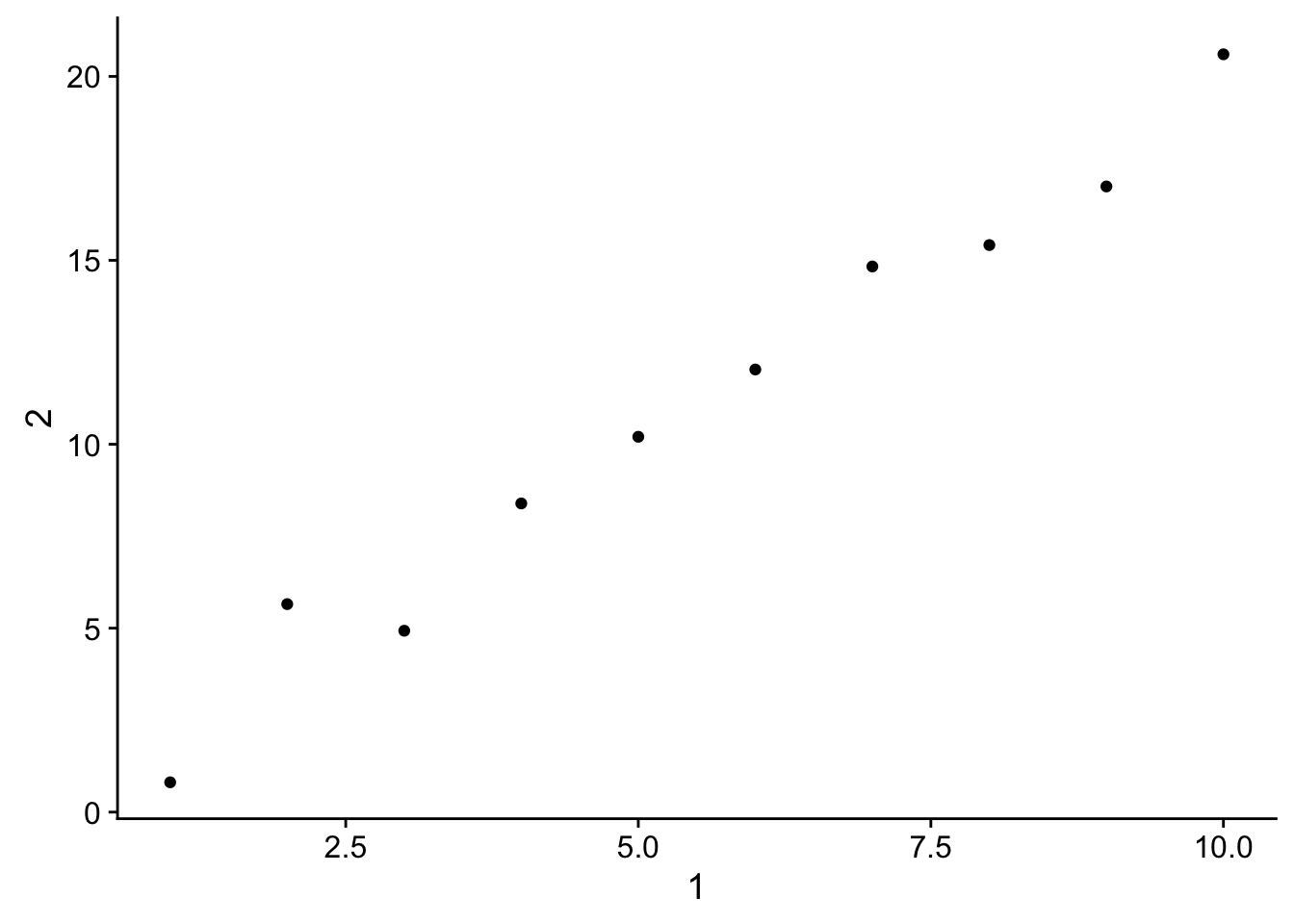
4c. Creating a new column called 3 which is 2 divided by 1.
annoying %<>% mutate(`3` = `2` / `1`)
annoying## # A tibble: 10 x 3
## `1` `2` `3`
## <int> <dbl> <dbl>
## 1 1 0.8098312 0.8098312
## 2 2 5.6539499 2.8269749
## 3 3 4.9305919 1.6435306
## 4 4 8.3908638 2.0977160
## 5 5 10.2030659 2.0406132
## 6 6 12.0321384 2.0053564
## 7 7 14.8327877 2.1189697
## 8 8 15.4151563 1.9268945
## 9 9 17.0081136 1.8897904
## 10 10 20.6010352 2.06010354d. Renaming the columns to one, two and three.
annoying %>% rename(one = `1`,
two = `2`,
three = `3`)## # A tibble: 10 x 3
## one two three
## <int> <dbl> <dbl>
## 1 1 0.8098312 0.8098312
## 2 2 5.6539499 2.8269749
## 3 3 4.9305919 1.6435306
## 4 4 8.3908638 2.0977160
## 5 5 10.2030659 2.0406132
## 6 6 12.0321384 2.0053564
## 7 7 14.8327877 2.1189697
## 8 8 15.4151563 1.9268945
## 9 9 17.0081136 1.8897904
## 10 10 20.6010352 2.0601035# or
annoying %>% rename(one = "1",
two = "2",
three = "3")## # A tibble: 10 x 3
## one two three
## <int> <dbl> <dbl>
## 1 1 0.8098312 0.8098312
## 2 2 5.6539499 2.8269749
## 3 3 4.9305919 1.6435306
## 4 4 8.3908638 2.0977160
## 5 5 10.2030659 2.0406132
## 6 6 12.0321384 2.0053564
## 7 7 14.8327877 2.1189697
## 8 8 15.4151563 1.9268945
## 9 9 17.0081136 1.8897904
## 10 10 20.6010352 2.0601035- What does tibble::enframe() do? When might you use it?
From ?tibble::enframe: enframe() converts named atomic vectors or lists to two-column data frames. For unnamed vectors, the natural sequence is used as name column.
This might be useful if you have a named vector you can to build into a tibble. Lots of functions will return results in a list or names vector format when there are several values to be outputted.
- What option controls how many additional column names are printed at the footer of a tibble?
# ???28 Advanced ggplot2
28.2 Label
- Create one plot on the fuel economy data with customised title, subtitle, caption, x, y, and colour labels.
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(se = FALSE) +
labs(title = "My title",
subtitle = "My sub-title",
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
caption = "My caption",
colour = "Car type"
)## `geom_smooth()` using method = 'loess'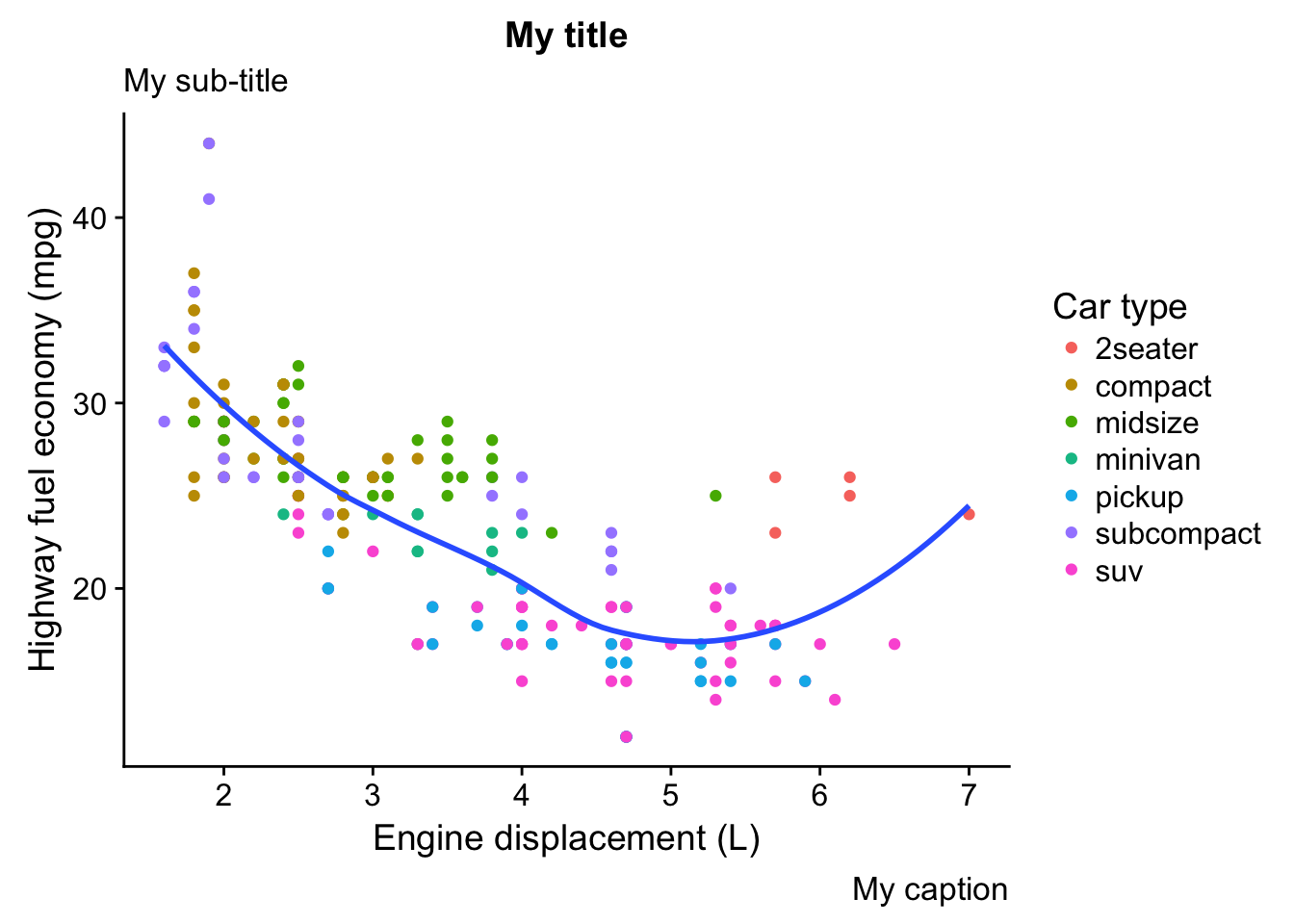
- The geom_smooth() is somewhat misleading because the hwy for large engines is skewed upwards due to the inclusion of lightweight sports cars with big engines. Use your modelling tools to fit and display a better model.
mpg_wo_2seaters <- filter(mpg, class != "2seater")
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(data = filter(mpg, class != "2seater"), se = FALSE)## `geom_smooth()` using method = 'loess'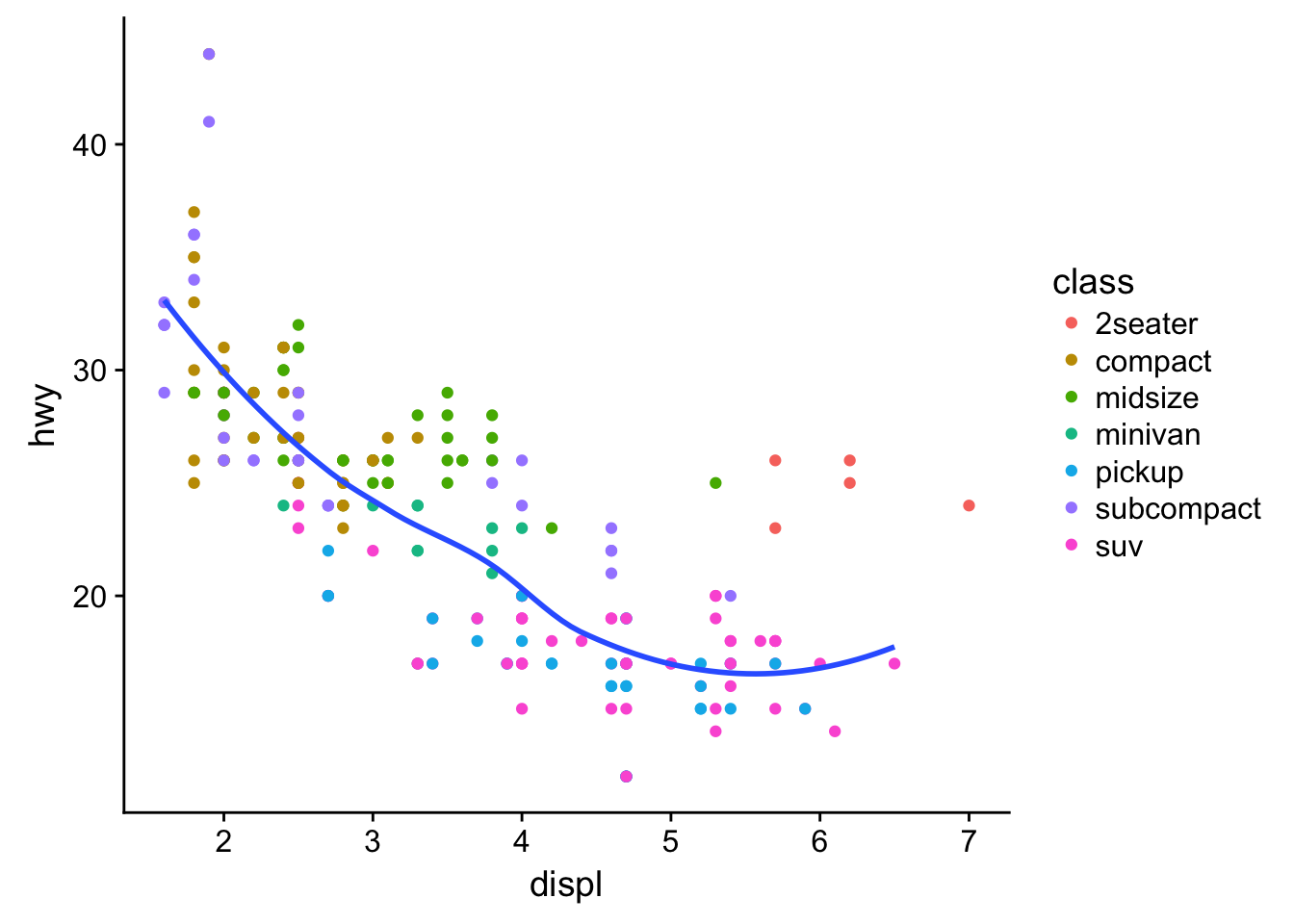
# just adjust the data going into the geom_smooth() layer- Take an exploratory graphic that you’ve created in the last month, and add informative titles to make it easier for others to understand.
data("ChickWeight")
ggplot(ChickWeight, aes(Time, weight, color = Diet)) +
geom_smooth(se = F) +
labs(title = "The Effect of Diet on Weight Gain",
y = "Weight (grams)",
x = "Time (days)")## `geom_smooth()` using method = 'loess'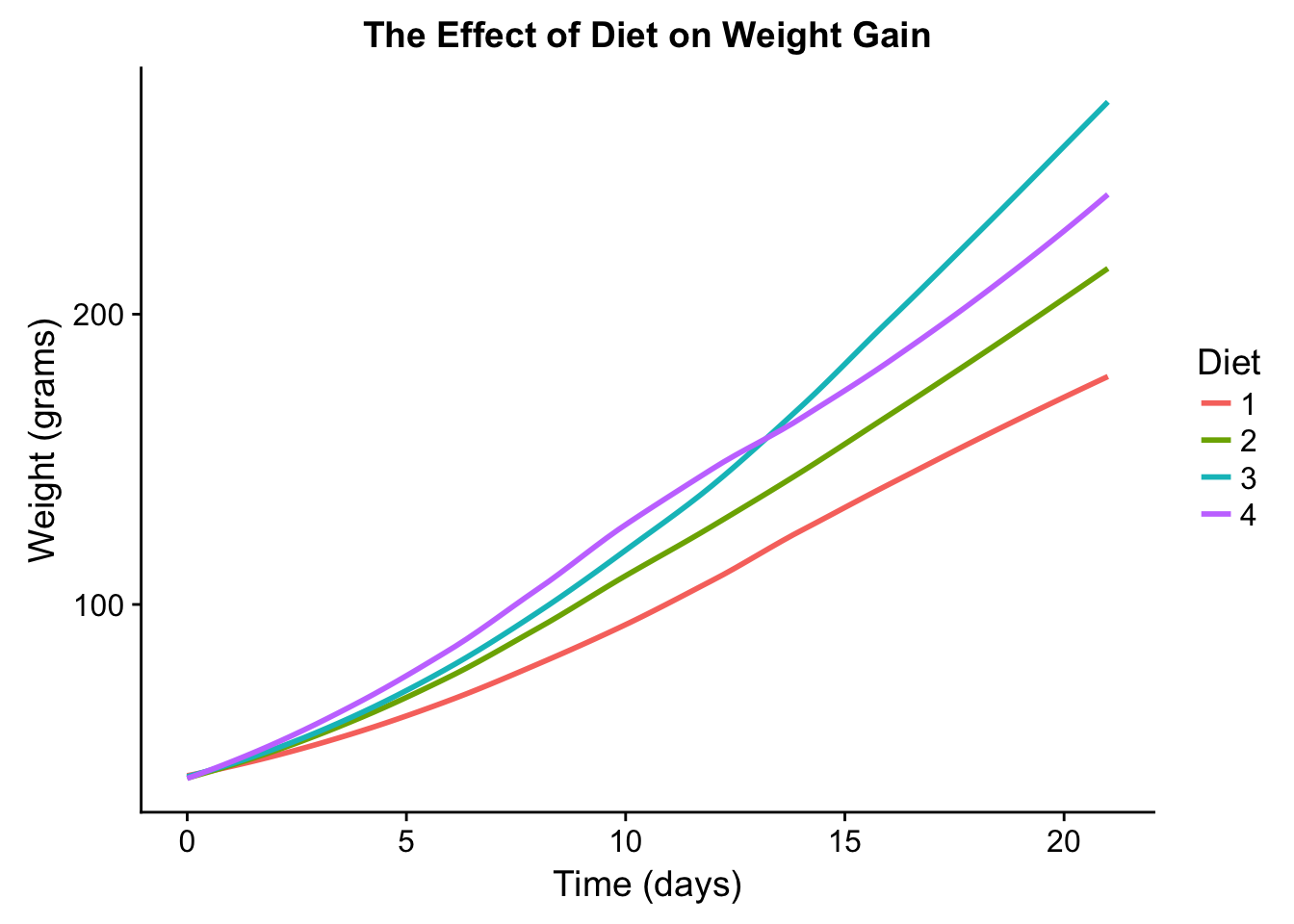
28.3 Annotations
- Use geom_text() with infinite positions to place text at the four corners of the plot.
corners <- tibble(x = c(0,1),
y = c(0,1))
ggplot(corners, aes(x,y)) +
geom_text(label = "bot_right", x = Inf, y = -Inf) +
geom_text(label = "top_right", x = Inf, y = Inf) +
geom_text(label = "bot_left", x = -Inf, y = -Inf) +
geom_text(label = "top_left", x = -Inf, y = Inf)
- Read the documentation for annotate(). How can you use it to add a text label to a plot without having to create a tibble?
?annotate
ggplot(corners, aes(x,y)) +
annotate("text", x = .5, y = .5, label = "Middle")
- How do labels with geom_text() interact with faceting? How can you add a label to a single facet? How can you put a different label in each facet? (Hint: think about the underlying data.)
mpg %<>% group_by(cyl) %>% mutate(avg_cty = round(mean(cty),1))
ggplot(data = mpg, aes(cty, hwy)) +
geom_point() +
geom_text(aes(label = avg_cty), y = 40, x = 15) +
facet_grid(~cyl)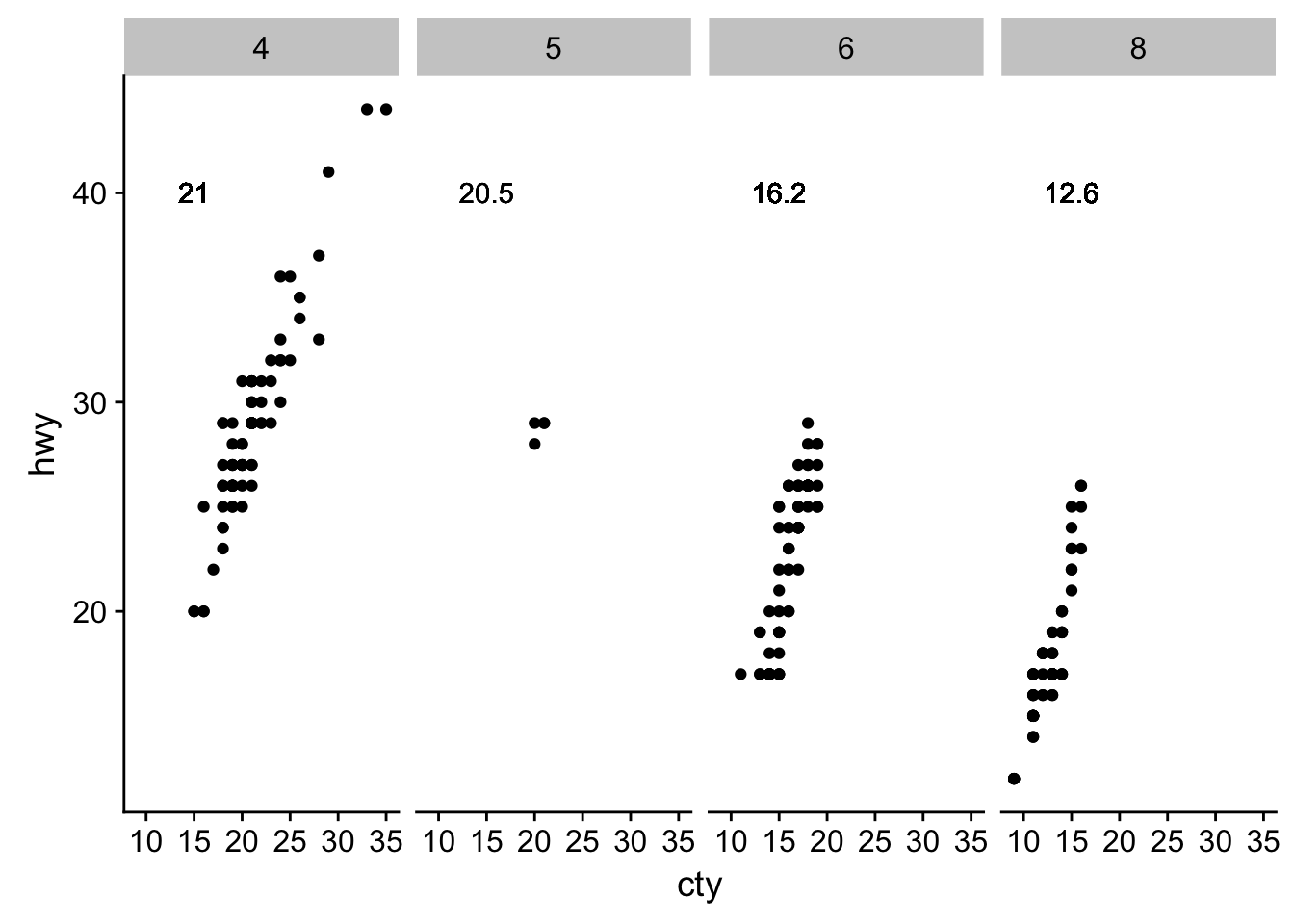
# delete unwanted labels for facets
mpg$avg_cty %<>% ifelse(mpg$cyl == 6, ., NA)
ggplot(data = mpg, aes(cty, hwy)) +
geom_point() +
geom_text(aes(label = avg_cty), y = 40, x = 15) +
facet_grid(~cyl)## Warning: Removed 155 rows containing missing values (geom_text).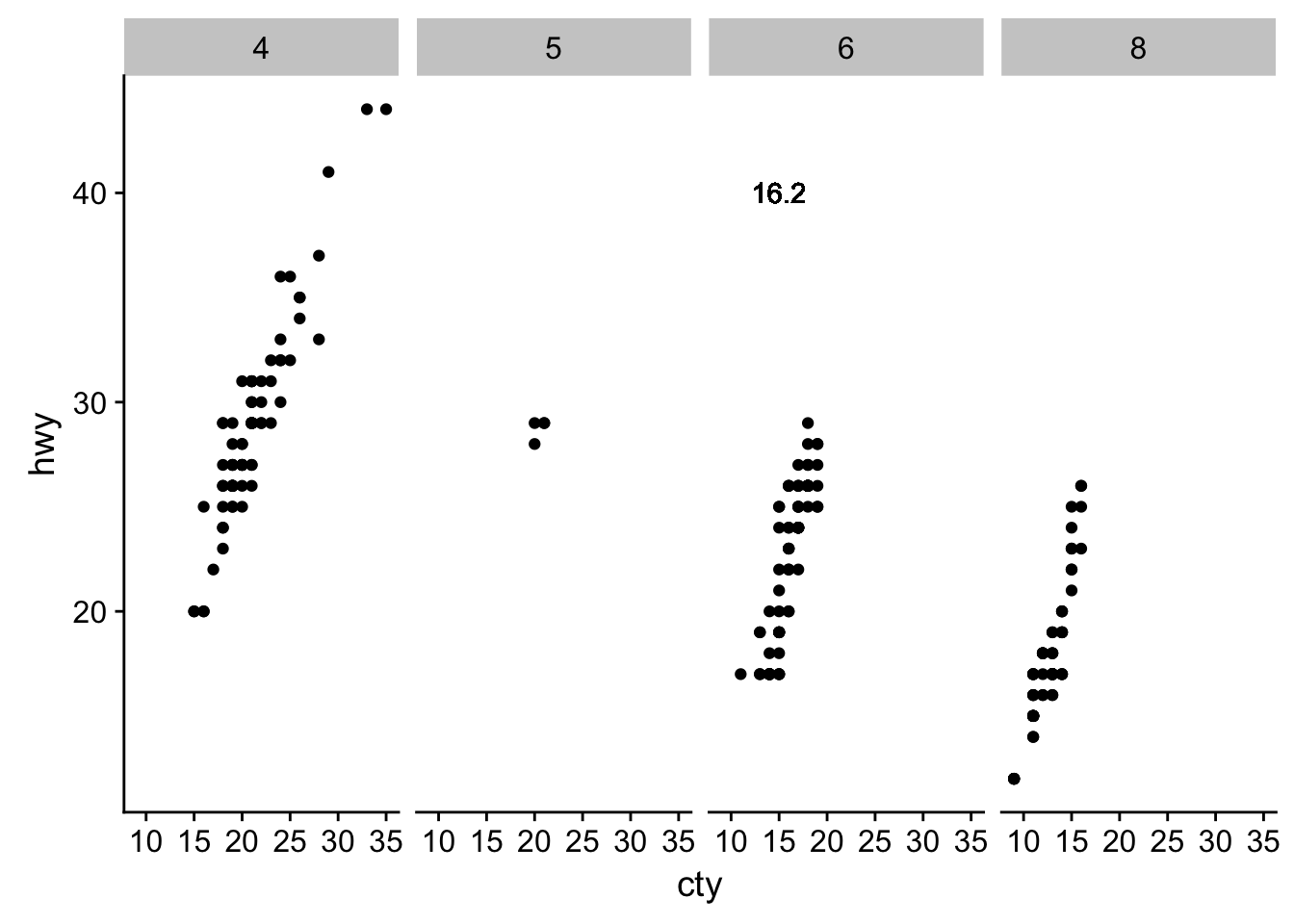
# really the best thing to do is use a seperate tibble
data(mpg)
avgs <- mpg %>% group_by(cyl) %>% summarise(avg_cty = round(mean(cty), 1))
ggplot(data = mpg, aes(cty, hwy)) +
geom_point() +
geom_text(data = avgs, aes(label = avg_cty), y = 40, x = 15) +
facet_grid(~cyl)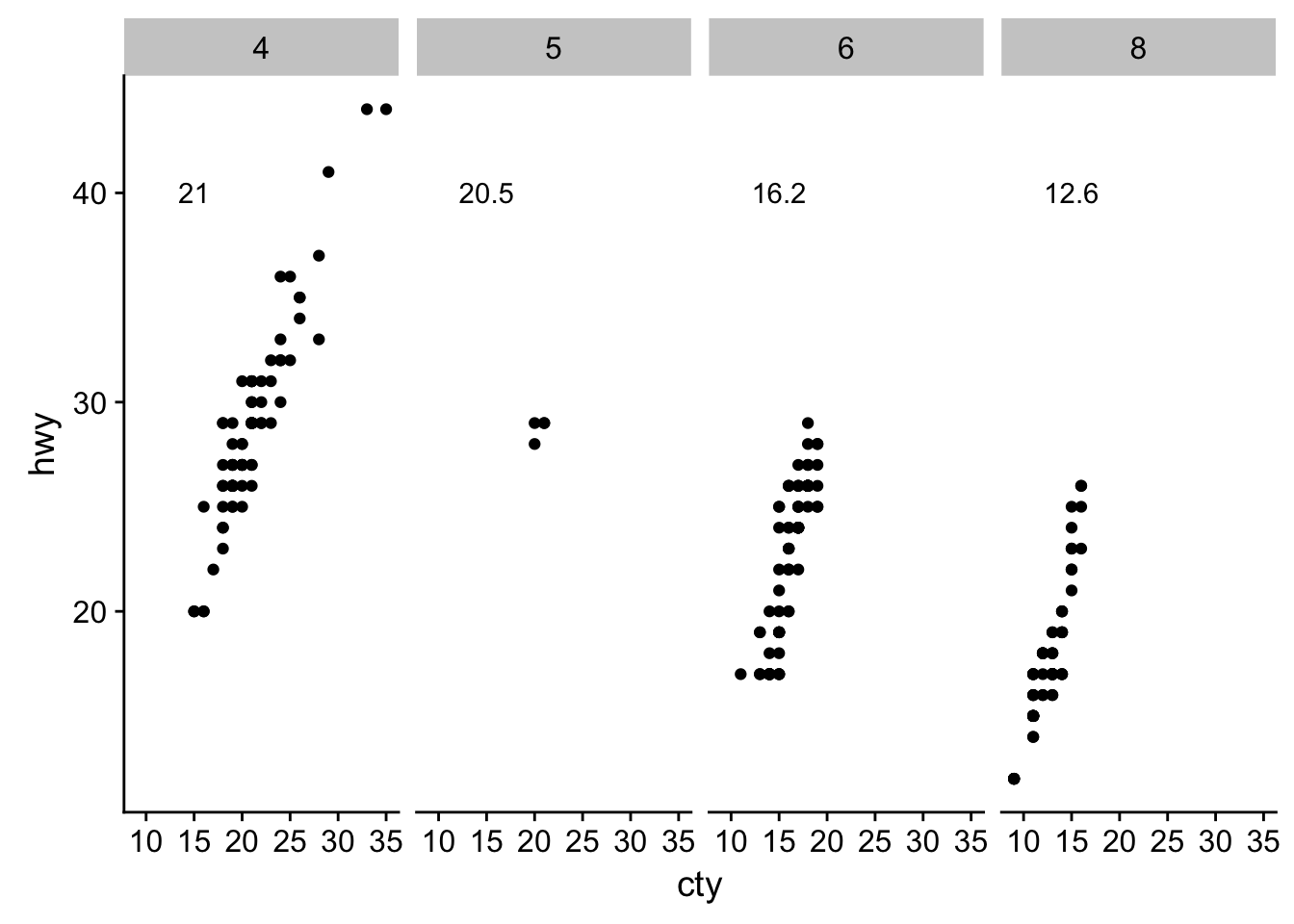
- What arguments to geom_label() control the appearance of the background box?
ggplot(data = mpg, aes(cty, hwy)) +
geom_point() +
geom_label(data = avgs, aes(label = avg_cty, fill = as.factor(cyl)), y = 30, x = 15, alpha = .5) +
facet_grid(~cyl)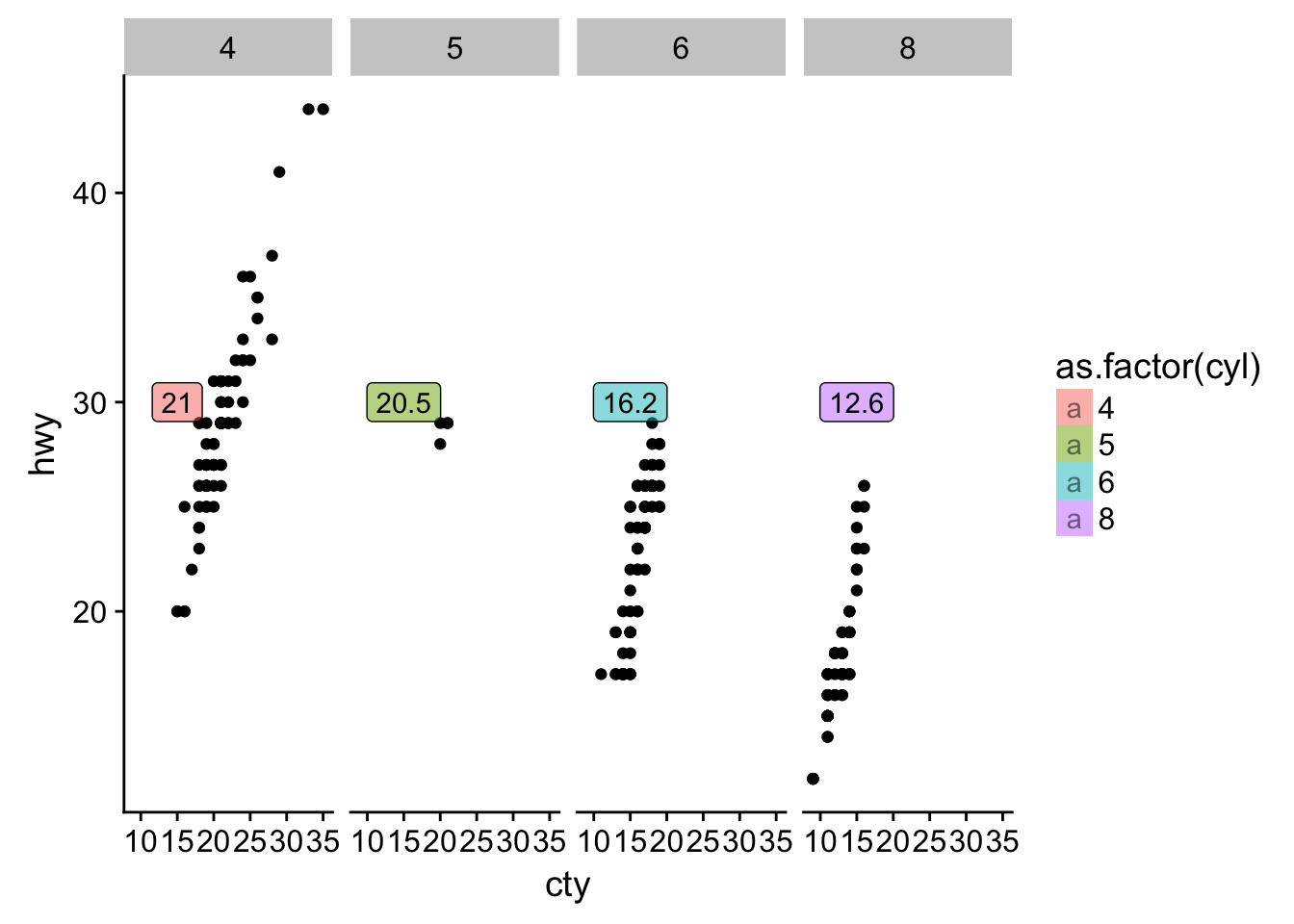
- What are the four arguments to arrow()? How do they work? Create a series of plots that demonstrate the most important options.
arrow()## $angle
## [1] 30
##
## $length
## [1] 0.25inches
##
## $ends
## [1] 2
##
## $type
## [1] 1
##
## attr(,"class")
## [1] "arrow"# need to complete :(28.4 Scales
- Why doesn’t the following code override the default scale? Because
?geom_hex()tells us that it is counting the number of cases in each hexagon and mapping that value to thefillaesthetic. So changing thecolorscale has no appreciable effect.
# the data from earlier
set.seed(1)
df <- tibble(
x = rnorm(10000),
y = rnorm(10000)
)
ggplot(df, aes(x, y)) +
geom_hex() +
scale_fill_gradient(low = "white", high = "red") + # now it works
coord_fixed()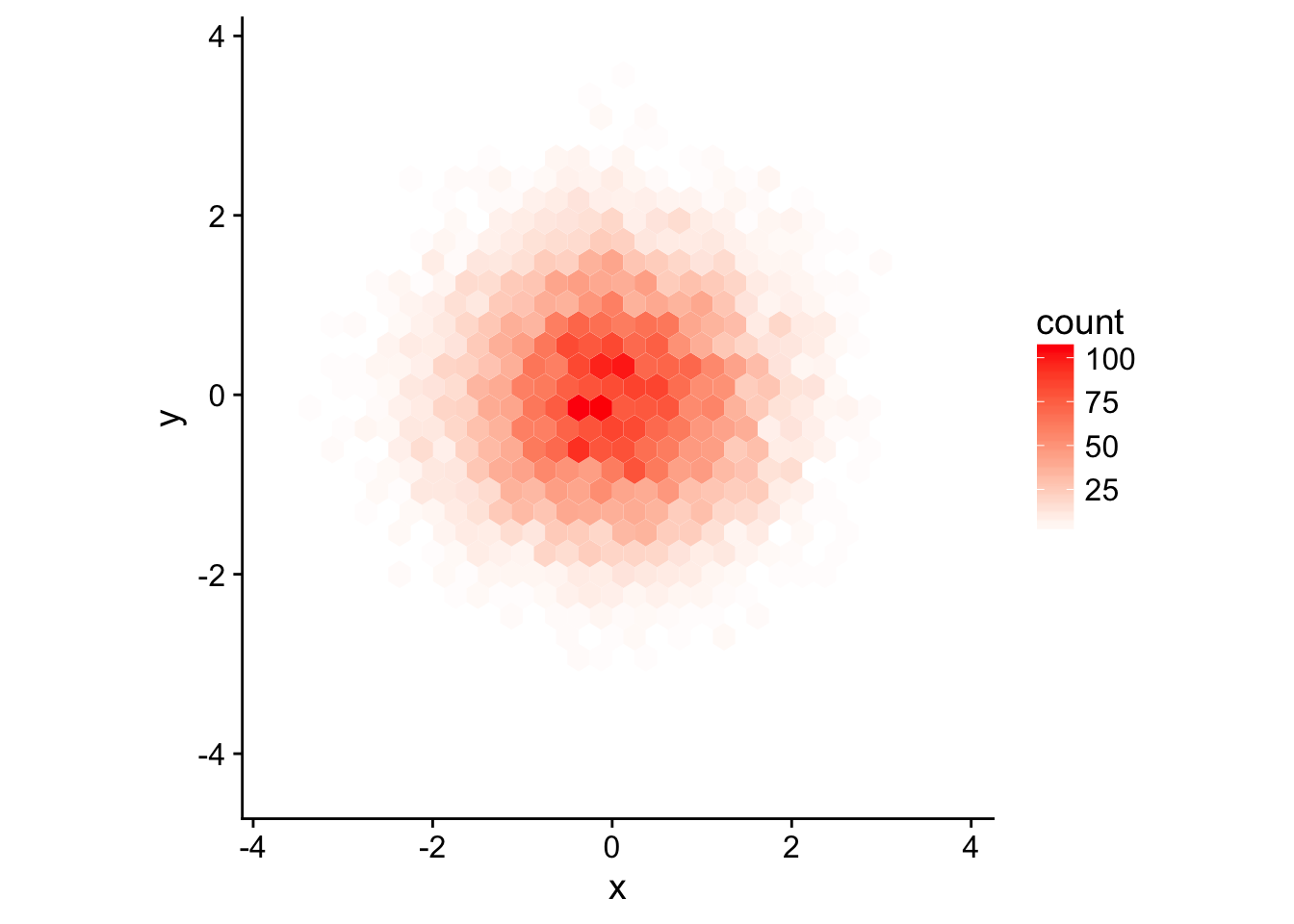
What is the first argument to every scale? How does it compare to labs()?
aesthetics, which is defining the names of the aesthetics a scale works with. This is similar tolabs()that takes a name-value pairs first and can also be used to label legends/aesthetics.- Change the display of the presidential terms by:
Combining the two variants shown above
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id, colour = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue")) +
scale_x_date(NULL, breaks = presidential$start, date_labels = "'%y")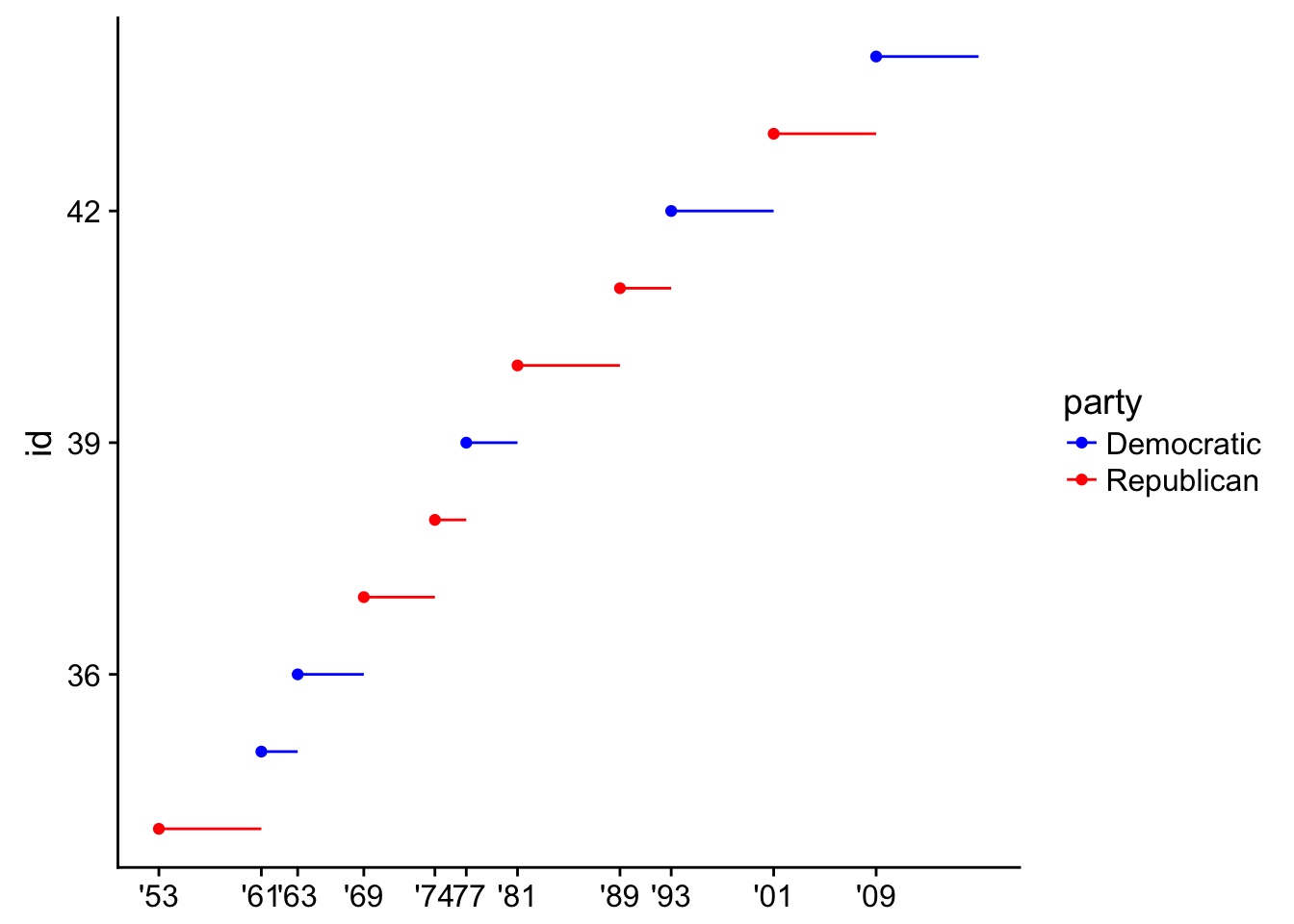
- Improving the display of the y-axis.
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id, colour = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue")) +
scale_x_date(NULL, breaks = presidential$start, date_labels = "'%y") +
scale_y_continuous(breaks = 34:44)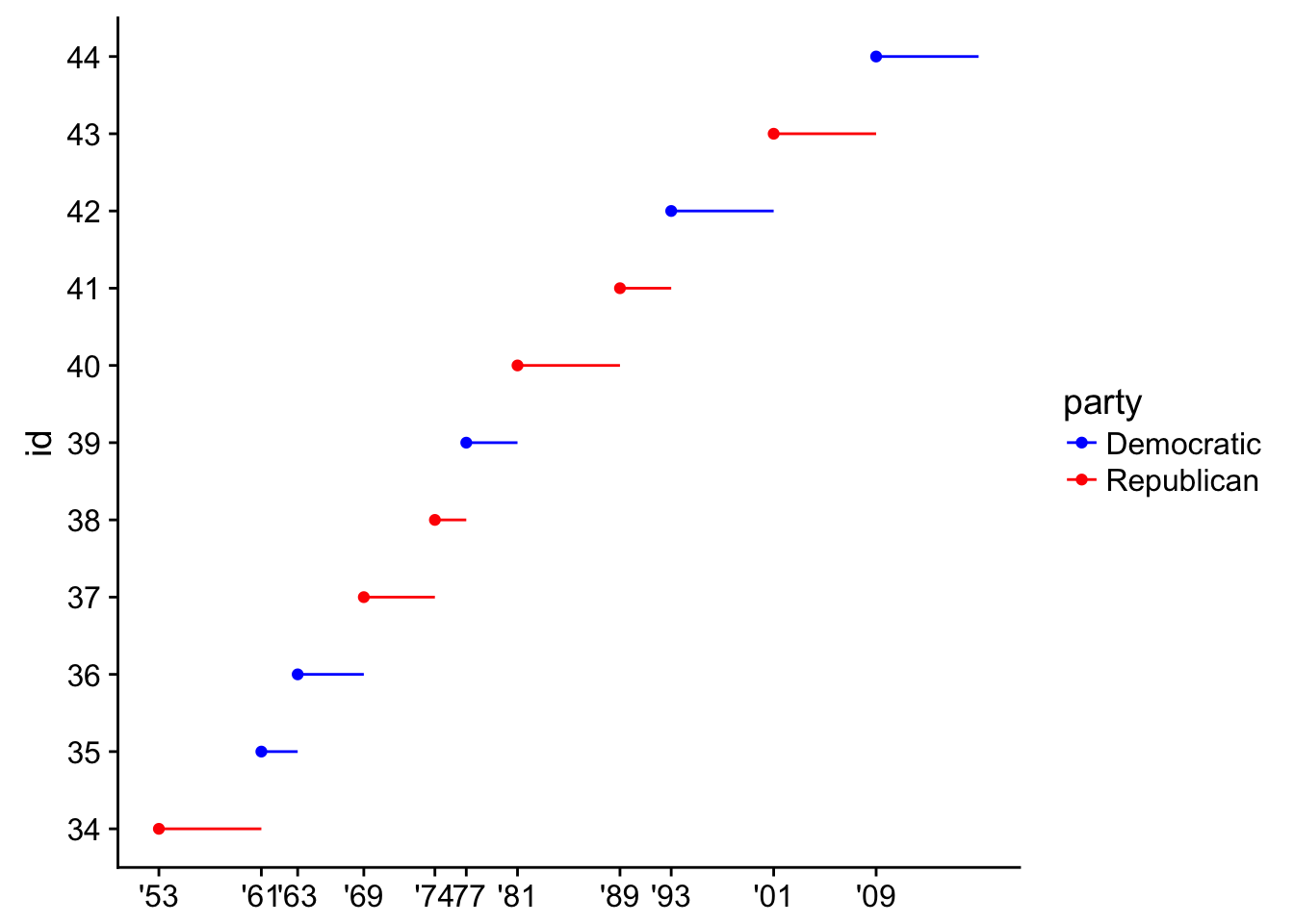
- Labelling each term with the name of the president.
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id, colour = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue")) +
scale_x_date(breaks = presidential$start, date_labels = "'%y", date_breaks = "4 years") +
scale_y_continuous(breaks = 34:44, labels = presidential$name) +
labs(x = "Is it there?")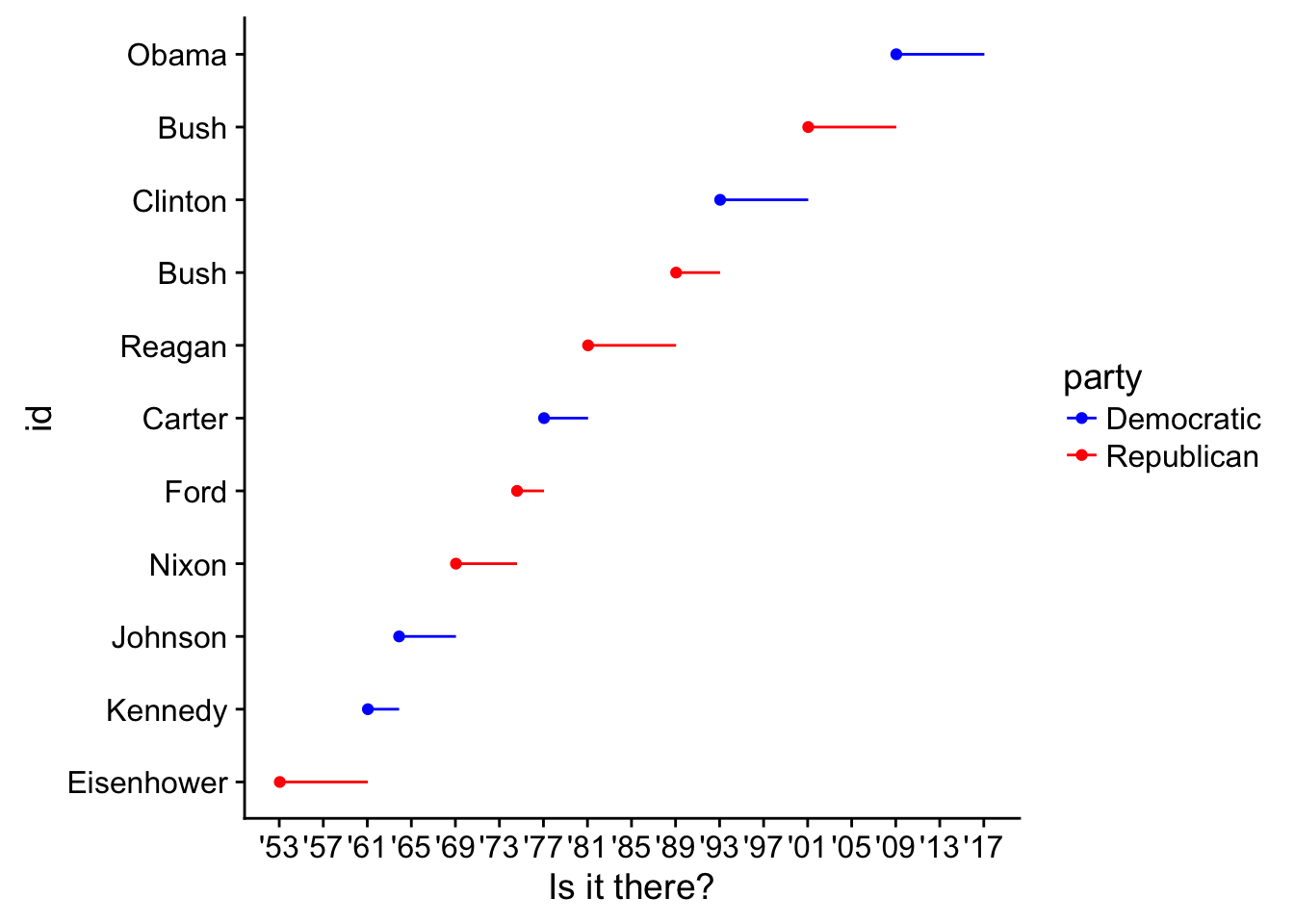
- Adding informative plot labels.
# code by Crystal Passmore
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id, colour = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue")) +
scale_y_continuous(breaks = seq(34, 44, by = 1), labels = presidential$name) +
labs(x = "year", y = "President", title = "Presidentail Terms")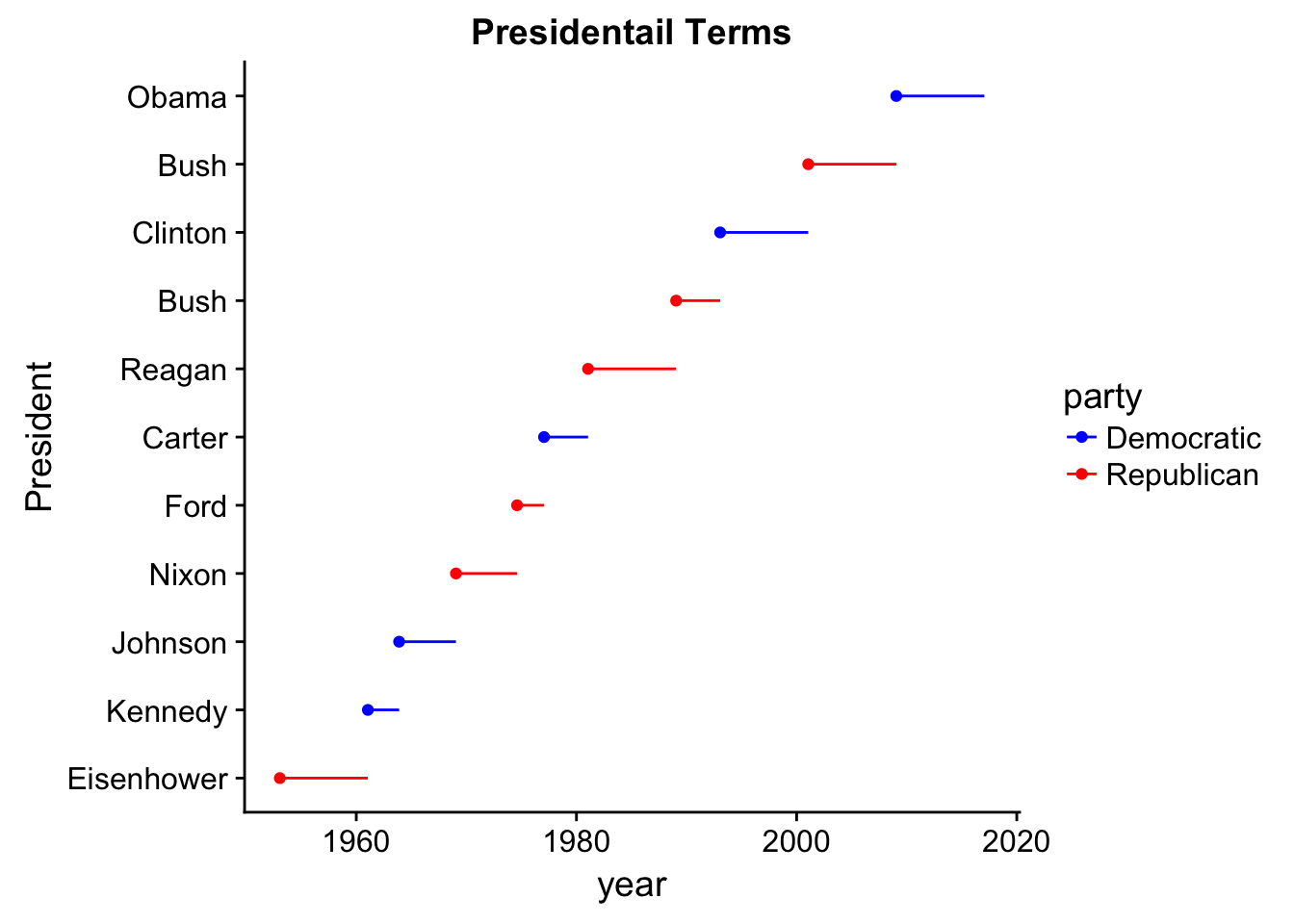
- Placing breaks every 4 years (this is trickier than it seems!).
presidential %>%
mutate(id = 33 + row_number()) %>%
ggplot(aes(start, id, colour = party)) +
geom_point() +
geom_segment(aes(xend = end, yend = id)) +
scale_colour_manual(values = c(Republican = "red", Democratic = "blue")) +
scale_y_continuous(breaks = seq(34, 44, by = 1), labels = presidential$name) +
labs(x = "year", y = "President", title = "Presidentail Terms") +
scale_x_date(date_breaks = "4 years", date_labels = "%y")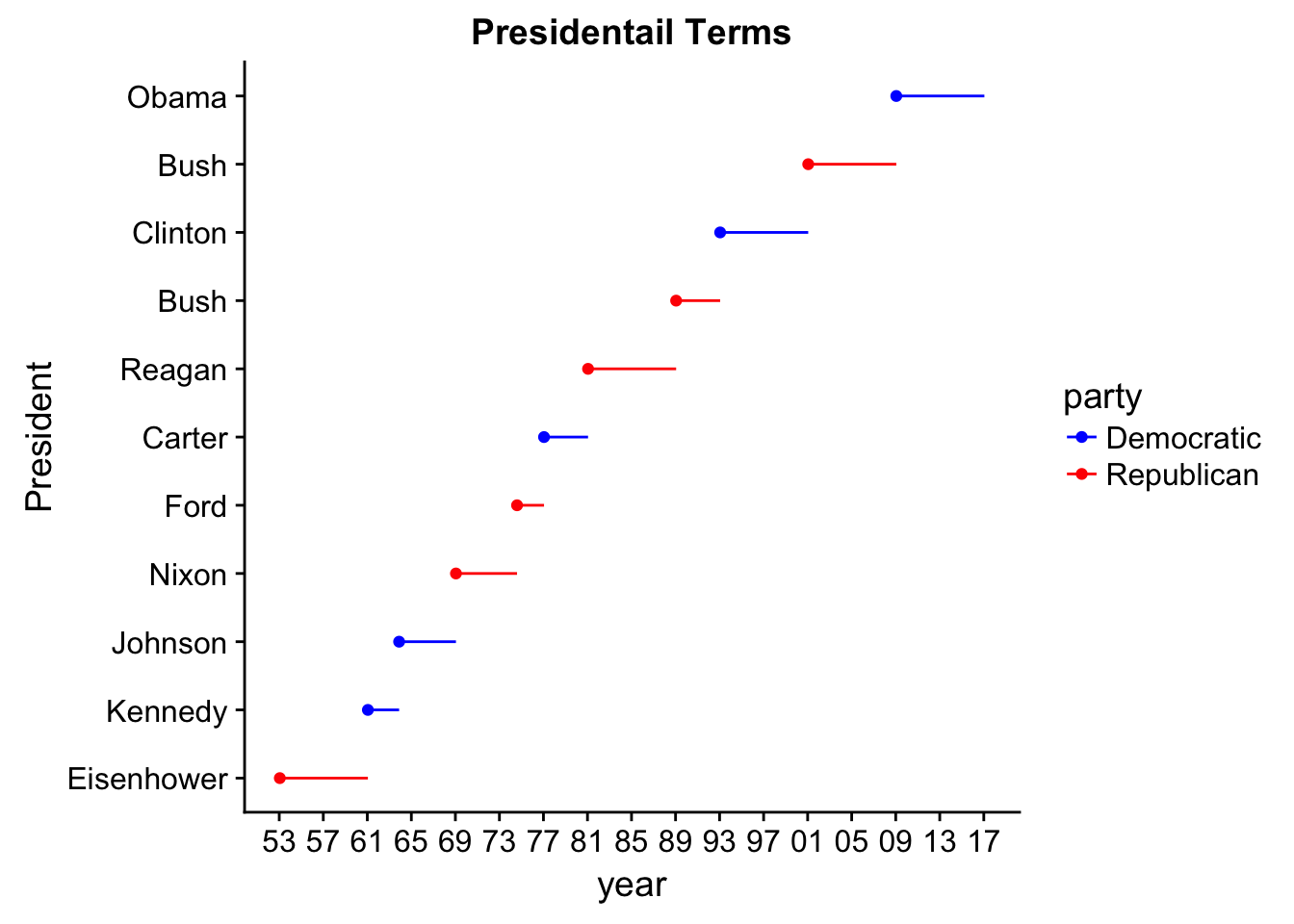
- Use override.aes to make the legend on the following plot easier to see.
ggplot(diamonds, aes(carat, price)) +
geom_point(aes(colour = cut), alpha = 1/20) +
guides(color = guide_legend(title = "Because",override.aes = list(alpha = 1, shape = 24, size = 4)))